![]()
最新記事公開時にプッシュ通知します
![]()
【後編】TypeScript×関数型×DDDで、ユニットテストが激減。実践の全貌とTips【Open Developers Conference 2024 レポート】
2024年11月18日


2024年9月7日に開催された Open Developers Conference 2024。本レポートでは書籍「関数型ドメインモデリング」翻訳者・猪股健太郎氏と、関数型プログラミングでアプリケーション開発に取り組む株式会社一休CTO・伊藤直也氏のセッション「関数型プログラミングのパラダイムはアプリケーション開発に必要なのか?」をご紹介します。
本セッションでは最初に、関数型プログラミングで設計・実装を行う方法論として、猪股氏が書籍「関数型ドメインモデリング」の内容を紹介し、その内容に基づいて、伊藤氏が実践例として自社の取り組みを紹介しています。
後編となる本編では、伊藤氏の発表内容を一部再編成してレポートします。
関数型でプロダクト開発に取り組むことで、ユニットテストが激減し、例外エラーも出なくなる? 現場で工夫していること、気をつけていること、また、現時点でのデメリットについても、率直に紹介しています。
※文中の「補足」は、発表後の猪股氏・伊藤氏双方の質疑応答をまとめて、本編内の関連箇所に記載しています。
- 書籍「関数型ドメインモデリング」の通り実践していること、そうでないこと
- 型で固める。ドメインオブジェクトの変更は「関数適用の状態遷移」で表現
- ユースケースはworkflowとして、小さな関数をいくつも合成してつくる
- 関数型スタイルはドメイン層にしか用いない。オニオンアーキテクチャの威力
- 「型」を最大限に生かすと、ユニットテストが減る
- TypeScriptである以上、面倒な実装も。特に「Result型パズル」が難所
書籍「関数型ドメインモデリング」の通り実践していること、そうでないこと
伊藤:株式会社一休の伊藤です。よろしくお願いします。私の会社では、猪股さんの翻訳書「関数型ドメインモデリング」の内容を参考に、実際にSaaSをつくっています。

伊藤:今つくっているのは飲食店向けのいわゆる予約台帳で、大きな業務アプリケーションで、かつ業務で使うものです。バックエンドは TypeScript で、GraphQL です。予約、空席管理、配席、決済など様々な機能があるのですが、このぐらいの大規模な業務アプリケーションでも「関数型ドメインモデリング」の内容を実践することで、比較的堅牢に開発していけると感じています。今日は実際にどうやって、TypeScript で関数型を使って開発しているのか、簡単に紹介します。
簡単に言うなら、基本的には型でめちゃくちゃ固める、という感じです。シャレではなく。ただし、実は書籍の通りにやっていることと、そうでないことがいくつかあります。

伊藤:この本の内容で実践しているのは、まずドメインオブジェクトを型で表現することと、エラー処理にResult型を積極的に使うこと。いわゆる例外とかも大域脱出を使わないで表現する。これらは実際にやってみて、すごくいいなと思っています。
対して、書籍にない方法を実践している部分もあります。TypeScript だから、また、書籍で言っていることはちょっと違うなと感じて取捨選択した点、どちらもあります。
前者としては、書籍では「リポジトリパターンはいらない」とあるものの、僕らは使っている、という点。TypeScript には Prisma という ORM (Object Relational Mapping) のライブラリがあります。これはいわゆる Rails の Active Record のようなものです。 Prisma が表現するのはデータモデルであって、ドメインモデルではありません。よって永続化にあたっては、ドメインオブジェクトのまとまり(集約:Aggregate)を Prisma のオブジェクトに変換するというレイヤーが必要です。だからリポジトリパターンを使ったほうがキレイに書けました。
後者としては、書籍ではワークフローに直接ドメインオブジェクトを定義するよう推奨されていたものの、僕は明確にそれだと難しいように感じたので、実践していません。既存のものと同じようなAggregate が出てきた時に、その Aggregate を共通化して定義するための場所が絶対に必要になるはずで、それをワークフローのファイルにに直接書かないほうがいいだろうなと。
1つ目は、特定のドメインオブジェクトが Aggregate に基づく場合、そのオブジェクトを状態遷移させる関数が他に振る舞いとして必要ですが、それをどこに書くべきか。これは書籍に言及がありませんでした。例えば Customer という Aggregate でドメインモデルを表現しているとします。このとき Customer の状態を遷移させて状態を変えるとか、Customer をアーカイブ済みにする、といった関数があるとして、それはどこに置いておけばいいのか? Customer というファイルに型定義をまとめ、Customer に関する関数はその下に置いておく。
こうして整理していくと、結局はオブジェクト指向の時と同じように、データ構造があってそれに紐付くふるまいを近く書いていくのが正となります。書籍にないからと特別なことをやっているわけではなく、既存の考え方に沿うのが最適なのではないかと考えて実践しています。
2つ目は、本に書いていたかは定かではありませんが、CQRS (Command Query Responsibility Segregation、コマンド・クエリ責務分離) の考え方を反映すること。読み取りと書き込みを分けろという考え方ですね。
僕たちのアプリケーションは GraphQL のバックエンドでつくっているので、データベースの Record にかなり近い粒度のオブジェクトを、フロントエンドが自由に要求できるようになっています。この仕様と、今回の書籍にあった「大きな Aggregate をつくってドメインモデルを一気に状態遷移させて保存しましょう」という大きな粒度の書き込み処理を行うというのは、考え方が全然違います。そのためおそらく、読み取り処理までドメインモデルを型で定義して、そこから復元する、といったレイヤリングで実装をしていると、パフォーマンスが低下してしまうでしょう。
だから現在の実装では、読み取り側は、データモデル、つまり Prisma のデータモデルを直接 GraphQL の Resolver に変換するくらいの薄いコードにしています。書き込み側に関しては、業務ロジックがすごく複雑になるので、書籍にあった手法を使っています。
型で固める。ドメインオブジェクトの変更は「関数適用の状態遷移」で表現
伊藤:では実際に TypeScript でどんな風に関数型で DDD をしているのか。

伊藤:スライドには色々書いていますが、まとめると、ドメインオブジェクト(例:Customerなど)を変更するときの状態遷移を、内部の状態を直接書き換えるのではなく、イミュータブルにする。すなわち、変更したいドメインオブジェクトのコピーをつくり、変更前と変更後のオブジェクトを、永続データとしてちゃんと残して書く。突き詰めるとおそらくこれこそが「関数型プログラミング」なのだと思います。
ではドメインオブジェクトは、どのように定義するのか?これは書籍にある通り、型で定義します。 TypeScript の場合はインターフェースを使います。サンプルコードがこちらです。
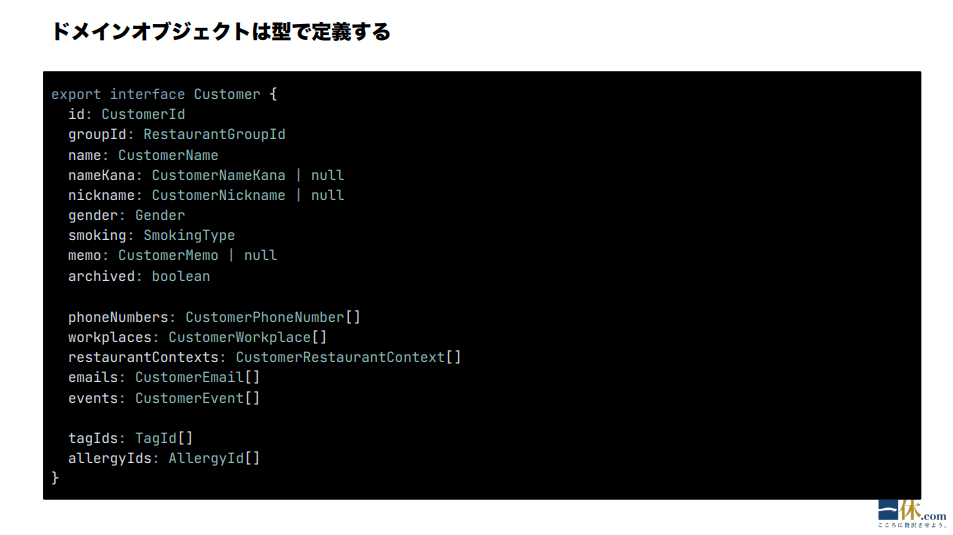
伊藤:インターフェースを使って、基本的にはプリミティブ型をあまり使わないで、各プロパティに1つ1つ型をつくっていく感じです。ここでは、interface をつくって、オブジェクトをつくるというだけ。クラスは使わないです。
繰り返しになりますが、特徴的なのは、オブジェクトの変更を「関数を適用したことによる状態遷移」として実装するところだと言えるでしょう。

伊藤:このサンプルコードのように、Customerオブジェクトを「アーカイブ済み」という状態に変更するにあたり archived プロパティを直接 false にするのではなく、分割代入のシンタックスを使って元のオブジェクト (customer) をコピーして、コピー時に archived プロパティを true にします。こうすることでオブジェクトはイミュータブルになり、さらに、必ず関数の引数に対して戻り値が返ってきます。
手続き型プログラミングにあたる「文」というのは、コンピューターに対する命令であり、戻り値を伴いません。例えば customer.archive() と書いて customer の中身の状態自体を代入「文」で書き換えると、オブジェクト自体が書き換わってしまいます。この場合戻り値は伴いません。文を使った計算機への命令を主体にした、手続き型プログラミングです。
一方、関数型では先にみたように「式」によって状態遷移を宣言します。式では入力に対し必ず戻り値が返ってきます。よって状態遷移関数においては、オブジェクトの状態が変化した後の値は必ず戻り値になる。極端にいうと、これを徹底するだけで、ほぼ関数型プログラミングと言ってもいいんじゃないかと思います。
ただ、もちろんこれだけだと恩恵はそんなに多くはありません。
続けて先ほどの Result型を使って、いわゆる Railway Oriented Programming に則って実装を進めていきます。
ユースケースはworkflowとして、小さな関数をいくつも合成してつくる
伊藤:次にユースケースの実装について。
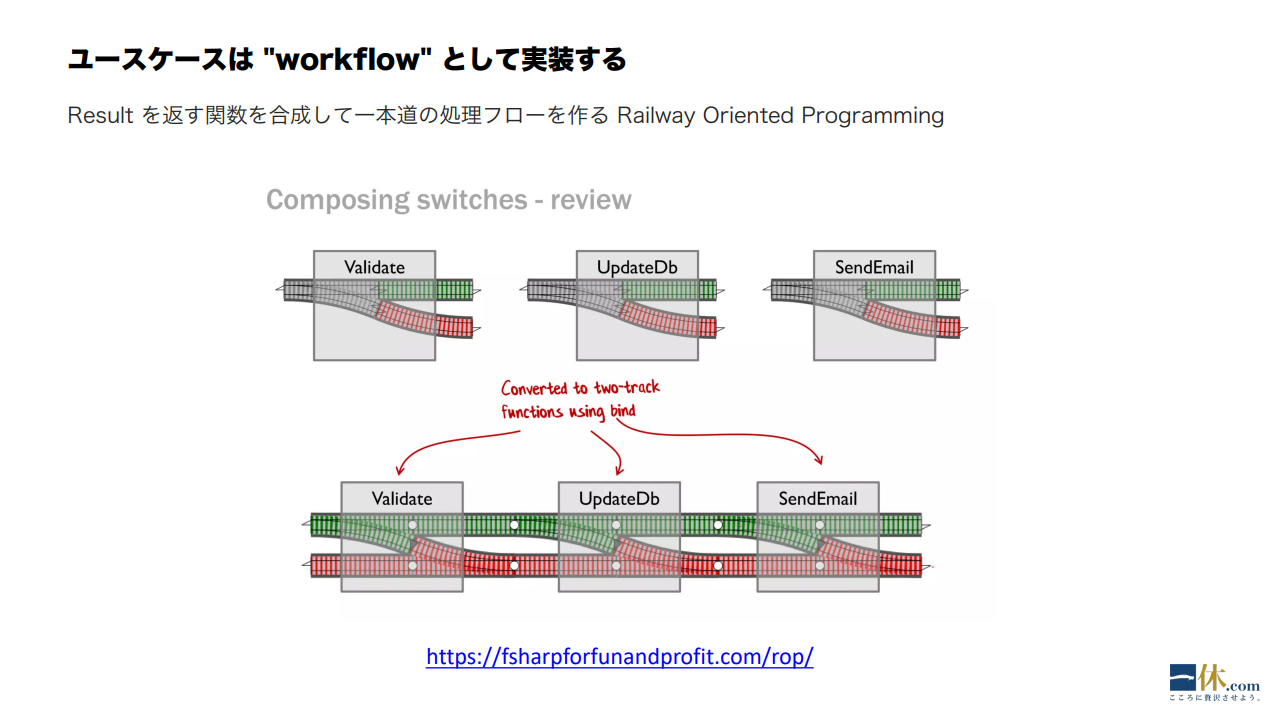
伊藤:このスライドにあるRailway Oriented Programming とは、小さい関数をたくさん書き、それを全部合成し、エラーがあれば途中でエラーになるし、なければそのまま実行プロセスが進んでいく、という方法です。この方法に沿ってユースケースの実装を進めます。
例えば顧客から、情報を抽出する、名寄せする、名寄せしたらその顧客で別の検索をしてあるフラグが見つかったら排斥する、といった一連の業務ロジックを、それぞれ小分けの関数にしていって、それを全部くっつける。処理の途中でバリデーションやドメインロジックが失敗するケースがあるので、戻り値は必ず Result 型で返すようにします。それがたくさん連なったものをワークフローといいます。
ワークフローを構成するサブステップの関数はすべて Result 型を返します。Result 型は合成が可能なので、一連のサブステップの関数を合成することで、それがワークフローになる、というわけです。
実際のワークフローの実装の一例がこんな感じ。入力はこういう型になり、出力はこういう型になる…と、ひたすら型を書いていきます。

伊藤:ただ、TypeScript の場合は、書籍で紹介されているF#と違って、組み込みでは Result 型が存在しません。僕の場合は NeverThrow というサードパーティーのライブラリを使っています。他にもEffect とか fp-ts などに、似たような Either 型や Result 型があります。TypeScript で関数型プログラミングを実践している人は、このあたりのサードパーティーライブラリを使っていることが多いと思います。
TypeScript で関数型スタイルで開発していく場合、サードパーティーの関数型プログラミング用ライブラリは使いすぎない方がいいと、個人的には思っています。
Result 型周りや、文脈付き計算の周りは、サードパーティーのライブラリを導入すれば確かにできる。しかしこの手のライブラリが提供する機能に頼りすぎると、TypeScript が本来標準ではサポートしてないパラダイムを多数取り入れたプログラミングスタイルを取らざるを得ません。開発当初はそれが問題にならなくても、5~10年と続けていくと、そのレイヤーがかえって邪魔になって、新しいことを取り入れられない、といったことが容易に起こり得る。だからこそ、もともとその言語に組み込みで備わっているものを素直に使ってやっていくのが一番だろう、とは考えています。
ただやはり、業務アプリケーションで例外を扱い始めると、その途端に大域脱出を使うなど、フローの分岐を自分たちで管理しなくてはならなくなり、せっかく関数型で得てきたメリットがスポイルされてしまいます。ここだけはどうしても Result 型に頼りたかった。そのため僕の場合は、NeverThrow という、Result 型だけを提供するライブラリだけを入れています。
伊藤:NeverThrow を用いた Result 型でのドメインロジックの書き方の一例は、以下の通りです。中身は基本的に全部イミュータブルになっています。
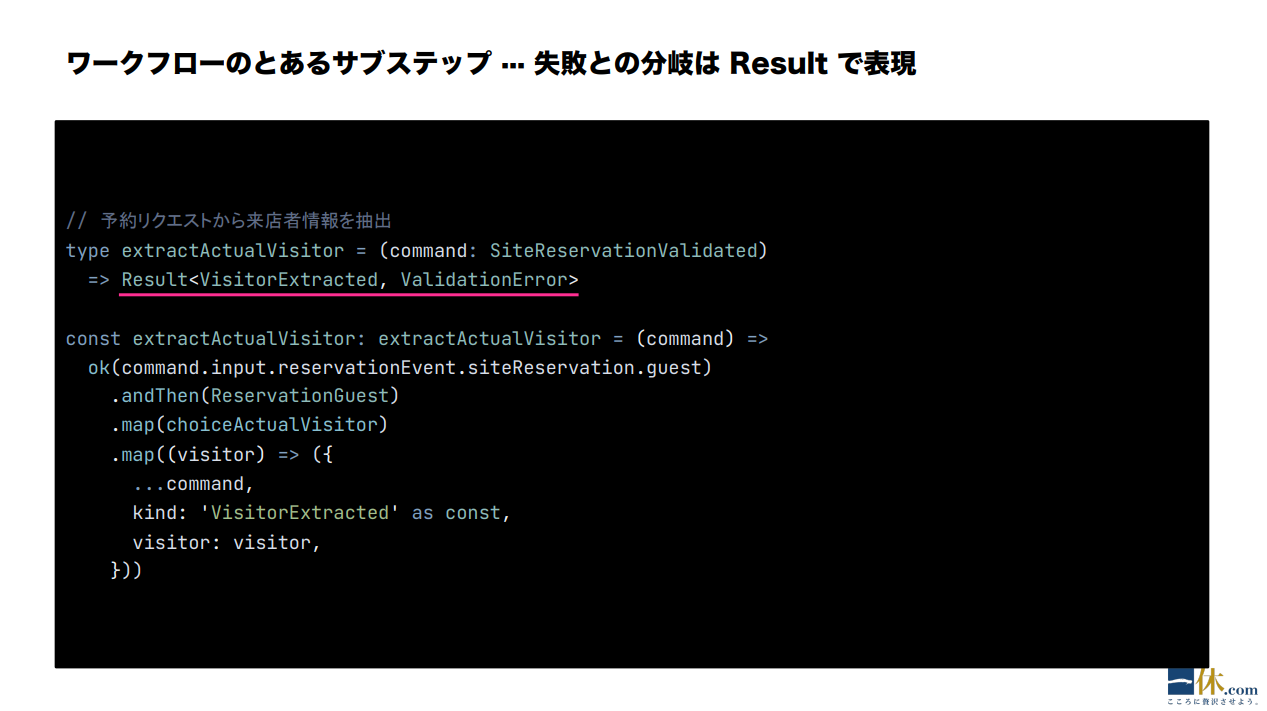
伊藤:こうして Workflow の型を書き、型に応じたサブステップを全部書いて、これらを最後に全部合成すると、こんな感じ。
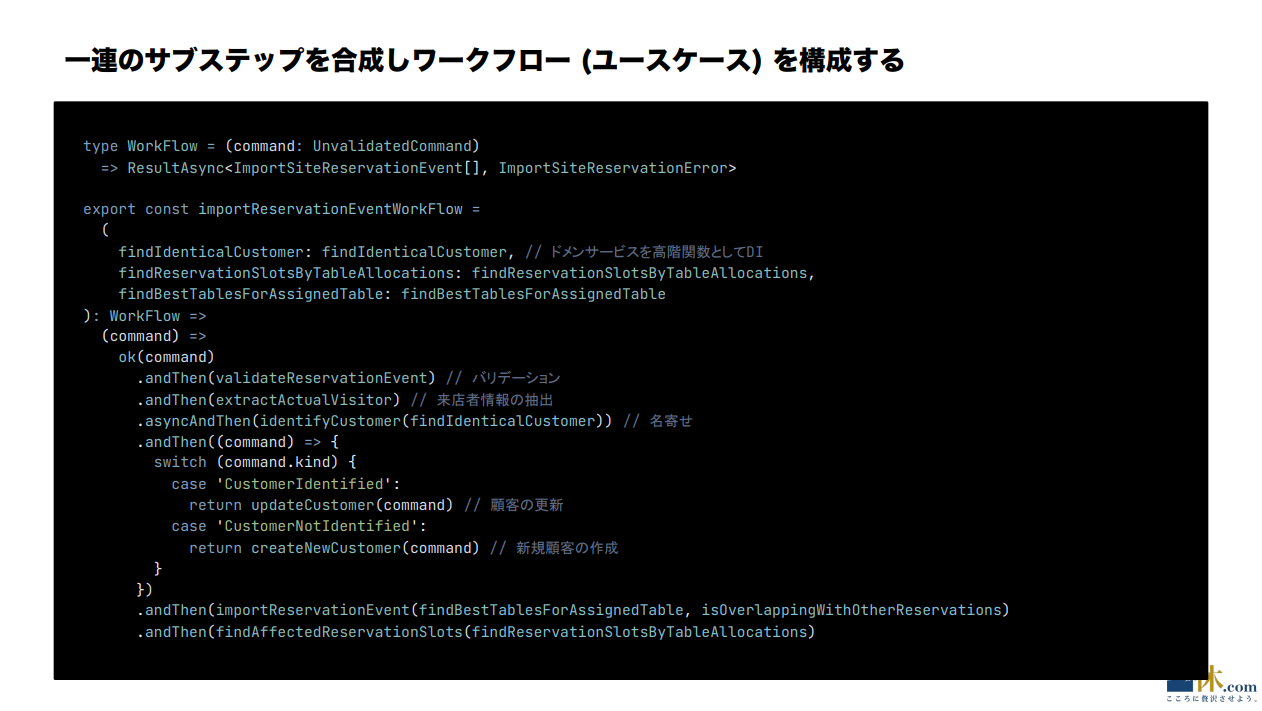
伊藤:この WorkFlow ではまず最初にバリデーションが走って(.andthen(varidate Reservation Event))、そこから実際の来店者を抽出して(.andthen(extractActualVisitor)、名寄せして(.asyncAndThen(indentifyCustomer(dindIdenticalCustomer)))、その顧客が既に存在しているなら顧客の内容を更新して、いなかったら新規顧客を作成する。その後、顧客に一番マッチする空席を見つけて、その空席を実際に割り当てる、といったドメインロジックを表現しています。Customer の状態が全て関数で1つ1つ変わっていくように表現されていて、それらを Result 型で合成してくっつける。
途中の、ok(command) の後に andThen、asyncAndThen が出てくるところが、まさに Result 型を合成しているコードになっていて。前のロジックが成功したら次のロジックを実行する、全部成功したら成功状態の Result が返り、途中で失敗したら失敗状態の Result が返るようになっています。
関数型ドメインモデリングの実装では、このような方法でほかのドメインロジックも表現していって、ワークフローを構成します。基本的には型でオブジェクトを定義して、状態遷移関数を先程の状態遷移モデルで書いて、Result で合成する。これだけでドメインロジックを構成できる。なので、実装において特殊な知識が大量に必要になるわけじゃないんです。なお、今回はほかの細かいところ、例えば関数のカリー化と部分適用でDIするなどといった話は割愛します。
そして、この関数型スタイルで実際に実装するときに、今紹介したような書き方をするのは、実はドメイン層だけなのです。
関数型スタイルはドメイン層にしか用いない。オニオンアーキテクチャの威力
伊藤:ドメイン層以外の I/O に関わる層は、今まで通り手続き型的に書きます。
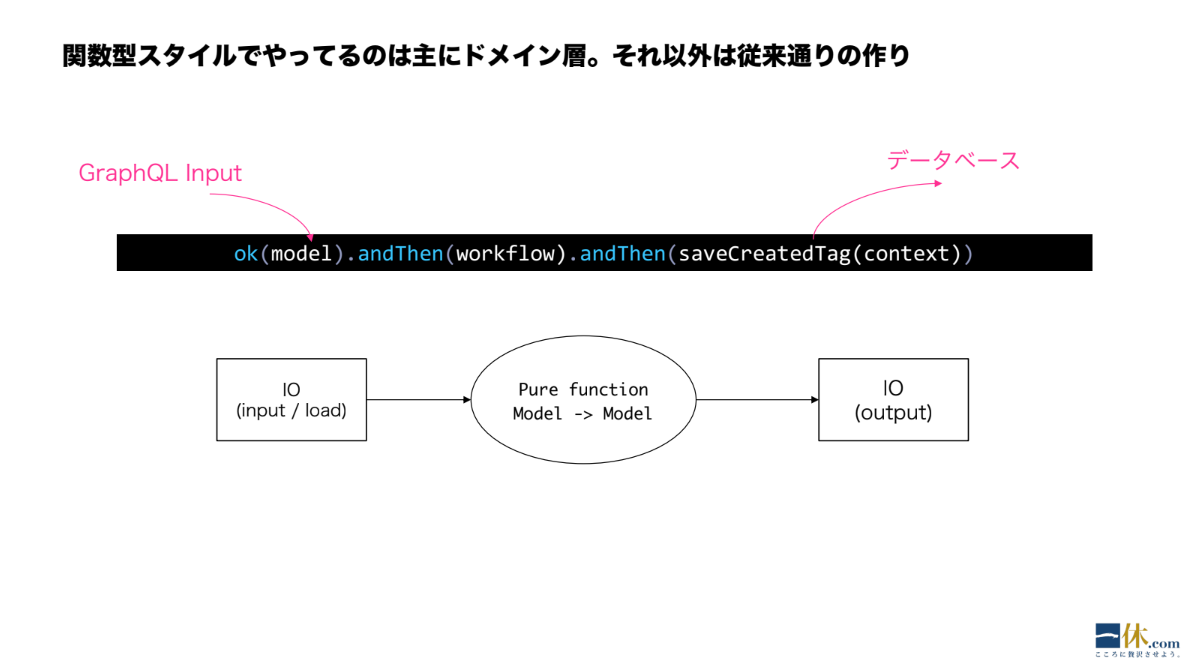
伊藤:例えば GraphQL から入力を受け取ったり、あるいはドメインロジックを実行した後にできあがった、状態遷移後のドメインモデルをデータベースに保存するといったところですね。
この図のように外側に I/O があって、真ん中に先ほど紹介した、純粋関数が書かれたドメインモデルのワークフローがある、というのが基本的な流れになります。つまりオニオンアーキテクチャです。クリーンアーキテクチャと言ってもよいです。
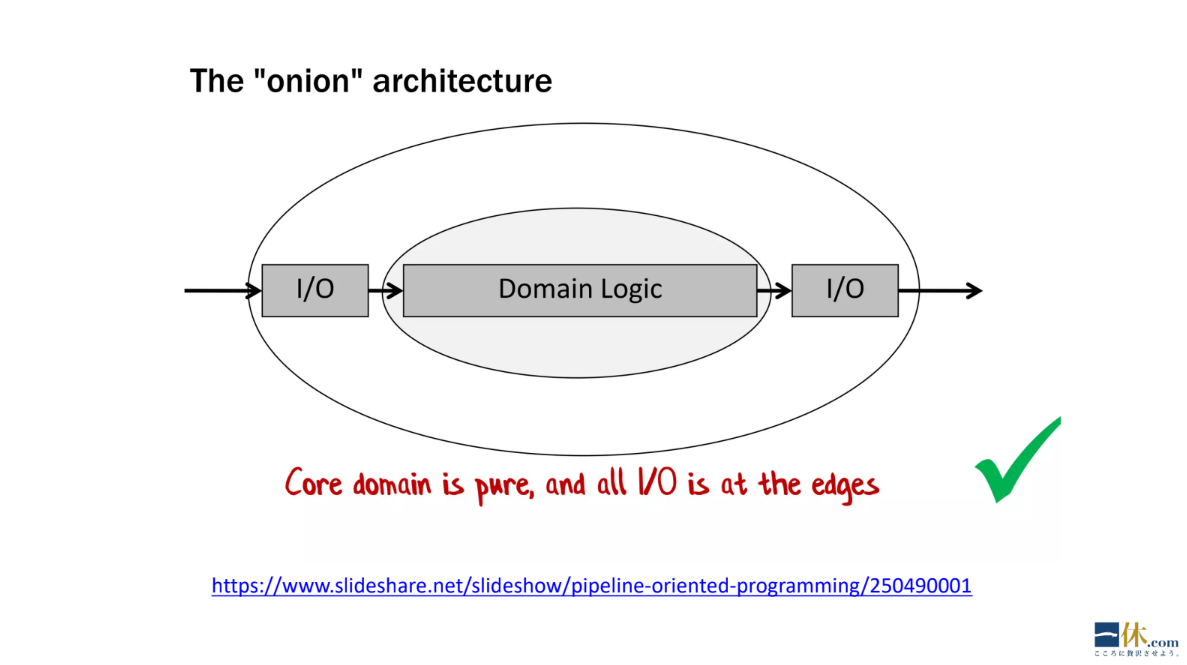
伊藤:中心にドメインモデルやコアドメインロジックを置いて、その周辺に I/O など副作用のあるものを繋げていく、というふうにすると、きれいに分離できる。
というわけで、システム全体の実装は従来の実装とそれほど変わらないです。アプリケーション全体は従来通りオニオンアーキテクチャになっていて、ドメインレイヤーは、関数型といっても、オブジェクトの構造を型で定義して、関数適用と状態遷移でイミュータブルで明示的に表現して、失敗の分岐は Result で表現する。これだけですから。よく「関数型でアプリケーションを組むのは教育コストが高そう」と言われますが、実際はそこまでではないです。
1つは、型定義をする際、不必要な状態をつくらないためにユニオンで型を構成していくところ。直和を積極的に利用するところですね。慣れないうちは従来のオブジェクト指向的な考え方で直積で書いてしまいますから、最初にここでつまずいた人が多くいました。
もう1つは I/O の分離。この本には「ワークフローを徹底的に純粋関数にしよう」とありますし、関数型でやっていくならなおのこと、そうしないと意味がない。それが最初はうまくつかめなくて、例えば「新しいIDを採番したい(ドメインロジックの実行中にデータベースの値を見に行って持って来たい)のですが、どうすればいいですか」といった質問が多くありました。そういう際はカリー化を使って部分適用して、I/O を外に出してDIするんだと根気よく教えていきました。
あとは書籍後半の方に応用として少ししか解説がなかったところについては、自分たちなりどうすべきか考えるものが多くありました。例えばドメインロジックを実行した後にメールを送り、データベースを書き込み、他のクラウドサービスにイベント通知をする‥といった具合で、I/O をいくつも実行する場合などですね。
「型」を最大限に生かすと、ユニットテストが減る
伊藤:ではなぜ、わざわざ関数型で開発するのか? 堅牢性だけを目的にするなら、従来の手続き型の手法でもそう大差は出ないはずです。
ドメインレイヤーを関数型にする目的は、突き詰めて言えば「型」です。静的型付け言語をせっかく使うなら、型システムの力をなるべく発揮させたい。

伊藤:そして、静的型付けの静的検査に、なるべくその構造の分析を寄せていくと、その点についてはユニットテストを書かなくてよくなります。なぜならコンパイラが全部チェックしてるから。コンパイルが通れば、無駄な状態がないことを保証できる。ユニットテストでは、より本質的に、業務仕様テストすることに集中できるようになります。
そして先ほど話したような、関数適用によって状態遷移するようにコードを書いていると必ず、状態遷移前のオブジェクトと、状態遷移後のオブジェクトが、関数の引数と出力に出現します。するとそこに明示的に型を付けられるんです。また、失敗による分岐もエラー処理も Result 型を使って型で表現できるので、「このエラー、ハンドリングしてない」とか「ここのエラー処理が漏れている」などイレギュラーな動作が起きていれば、静的検査で全部わかるようになります。
つまり、関数型プログラミングすること自体が目的、というわけではなく、実は型や静的検査をより積極的に利用することが目的である、と考えています。
今使っている NeverThrow というライブラリは、サードパーティーライブラリ含む従来の関数が例外を投げた時に、その例外を Result に変換するという機能を持っています。
基本的にそういう例外が起こりやすいのは、外部の API を叩く際などネットワーク通信が発生するときと、あとデータベースに書き込んだり呼び出したりするとき。ここは I/O境界がはっきりしているので、その I/O境界のところで NeverThrow の fromPromise という、Promise を ResultAsync に変換する機能を使って、Result に変換します。そうすると「例外」ではなく、Result で全て処理できます。
我々は業務アプリケーションをつくって運用していますが、いわゆる例外を処理し忘れてサーバーが落ちたとか、500エラーになったといったことがほぼ起きていません。これまでのアプリケーションで起きていた、「ここのフロー実装し忘れていました」「ユニットテストでエッジケーステストをしていませんでした」といったことが原因で障害を起こすことはかなり減りました。堅牢性という意味でのメリットはものすごく大きいです。
型定義する際に、Nullable にするかどうかはかなり慎重に設計しています。せっかく代数的データ型でユニオンを使える状態で型を定義できるのに、そこで安易に null を使ってしまうと、業務使用上あり得ない状態をつくってしまい、堅牢性を担保できなくなります。
それを防ぐために、コードレビューで毎回「ここの null はいらないのでは」「ユニオンにできるのでは」と慎重に議論を重ね、本当に null が必要なところ以外は使わないようにしています。これも、先ほどお話した「null 踏んじゃってよくわからない障害が起きました」という事態を防ぐきっかけになっているかもしれません。
こうした動きも、この本が提唱する「型をベースにオブジェクトを定義する」「不必要な状態をつくらない」というコンセプトを、チームで強く意識しているからこそだと思います。
オニオンアーキテクチャでは、真ん中のドメインモデルやコアドメインロジックが大きいほど、周辺の I/O との分離をするメリットが大きくなります。ドメイン層が薄くて、例えばデータベースを読み取ってちょっと書き戻すくらいだったら、純粋関数で書いているメリットはそう大きくないかもしれません。だから、業務ロジックが大きくなってくればなってくるほど、今回の手法を使った時のメリットが大きくなる感覚はあります。僕がつくってるSaaSはかなり業務ロジックが複雑なので、そこがすごくマッチしていました。
従前のやりかたと関数型スタイルでのやり方で、よりドメインレイヤーの実装に集中できているかなどは、オブジェクト指向でやっていた時とそう大きくは変わっていません。そう感じられるかどうかはドメイン分析のより上流の影響を大きく受けるだろうと思っていて、この実装手法が直接関係するわけではないと思います。
TypeScriptである以上、面倒な実装も。特に「Result型パズル」が難所
伊藤:ここまでの話ではいいことだらけのように見えますが、実際は面倒なこともいくつかあります。
特に TypeScript で一番面倒なのが、Result 型を使った時。TypeScript には、いわゆる Haskell での do 記法や、F# のコンピュテーション式のように、コンテナに入った値の計算を書きやすくするプログラミングの支援機構がありません。そのため、Result がネストしてきた時、それをフラットにするようなコードを自分で全て書かないといけないんです。以下のサンプルコードが一例です。

伊藤:これは慣れていない人が書くととても複雑なコードになりがちで、ここはちょっと大変ですね。TypeScript が組み込みではサポートしてない Result 型を、サードパーティーライブラリでまかなうことのトレードオフだと思います。
もし、TypeScript と同じくらいWeb開発に向いていて、かつ関数型にもう少し振り切っていて、Result 型など組み込みのコンテナの型を持った言語があれば当然それを選びます。しかし現状はそのような良い言語はないので、今のところはこの面倒さを受け入れて頑張って書いています。
これは結構難しいですね。TypeScript は型の表現力が高いので、TypeScript には組み込みで存在していない型を表現することも可能です。書籍で扱っている F# にある代数的データ型は、TypeScript ではリテラル型とユニオン型を使えばエミュレートできます。Result 型もサードパーティーライブラリを持ってくれば使えますし。ここまで見たとおり TypeScript が持っている静的型付けに任せてアプリケーションを固めていける感覚もあり、これはかなりいいなと思っています。
しかし最後に「面倒なポイント」として触れた Result 型パズルは、同僚もみんなここが面倒だと話すくらいで、かなり開発時のオーバーヘッドが大きいです。文脈付きの計算、例えば Result や Optional、などを合成しようとした時に、合成するコードに対してシンタックスをフラットにするといった機能がないから、面倒でも与えられた API で書くしかない。これを頑張らなくてもいいように書ければ多分ベストではあります。ただ、TypeScript の標準仕様として Haskell の do 記法などに相当するものが取り入れられるかというと、ベースが JavaScript ということもありますし、将来的にも考えにくいのではないかと思います。
これらを踏まえると、現段階でバランスが取れているかははっきりと言い切れないかなと。
欲を言うなら、TypeScript に後付けで関数をオーバーロードすることができない点も気になります。
Haskell では型クラスがあって、既存の型クラスの中に自分が定義した型を入れることで、例えば「+」という演算子に別の意味を持たせることが簡単にできますが、これは TypeScript ではできない。正確に言うとオーバーロード自体はできるけれども、後から付けることができない。Scala や Rust でもこれはできますから、ちょっと足りないなとは感じます。そう大きな問題ではありませんが。
個人的に選べるのであれば Haskell を使います。Haskell を使えばおそらく、書籍「関数型ドメインモデリング」が提案する F# の手法と同じかそれ以上のことができるだろうと思います。
しかしチームで開発するとなると話は別です。Haskell でのチーム開発では、やはり書ける人を集めたり、Web開発に必要な様々な部品すべてを揃えるのが大変そうな印象があるので。チーム開発で、今日紹介した関数型のスタイルでの開発自体をより重視するなら、TypeScript ではなく Scala 3 を使うと思います。
伊藤:僕の話は以上です。
この書籍のサンプルコードも読みましたが、サンプルは大規模なアプリケーション開発は想定していないのではないかと思います。もしそうした現場で書籍の内容を実践したいなら、クリーンアーキテクチャなどのエッセンスを取り入れた方がいいんじゃないかと思いました。
猪股:そうですね。この書籍は入門書というか、分かりやすく書くために切り捨てているところも多々あります。書いていないことも考えて、実践しなくてはならない機会も多かったんじゃないかと思います。
今日話してもらったのはまさに実践した人の感想で、当然出てくる難しさだと思いますが、書籍としてはここまでの解説は現実的に難しい。なので今日のように、書籍の先は皆さんが実践して試行錯誤していっていただければと思います。
伊藤:ありがとうございました。
執筆・撮影:光松 瞳
関連記事
【後編】TypeScript×関数型×DDDで、ユニットテストが激減。実践の全貌とTips【Open Developers Conference 2024 レポート】

ミノ駆動さんに「なぜ負債解消にDDD?」と聞いたら、ソフトウェア開発の本質に気づかされた

【t-wada】自動テストの「嘘」をなくし、望ましい比率に近づける方法【Developer eXperience Day 2024 レポート】
人気記事

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】

インデックスを張るだけでは足りない。数億件の名刺データを扱うSansanのSQLパフォーマンス改善


