![]()
最新記事公開時にプッシュ通知します
![]()
【前編】関数型×DDDの設計と実装は、どう進めるべきか。書籍「関数型ドメインモデリング」翻訳者が語る【Open Developers Conference 2024 レポート】
2024年11月18日


書籍「関数型ドメインモデリング」翻訳者
猪股 健太郎
システムエンジニア、ソフトウェア開発者。BIPROGY株式会社勤務。各種業務システムに関する開発支援や開発標準策定等に従事後、数年間の米国駐在を経て帰国。近年はアジャイルソフトウェア開発を含む開発スタイル変革に携わる。『速攻入門 C#プログラミング すぐに現場で使える知識』(技術評論社、共著)、『プログラミングXamarin 上・下』(日経BP、監訳)、『.NETのクラスライブラリ設計』(日経BP、監訳)
2024年9月7日に開催された Open Developers Conference 2024。本レポートでは書籍「関数型ドメインモデリング」翻訳者・猪股健太郎氏と、関数型プログラミングでアプリケーション開発に取り組む株式会社一休CTO・伊藤直也氏のセッション「関数型プログラミングのパラダイムはアプリケーション開発に必要なのか?」をご紹介します。
本セッションでは最初に、関数型プログラミングで設計・実装を行う方法論として、猪股氏が書籍「関数型ドメインモデリング」の内容を紹介し、その内容に基づいて、伊藤氏が実践例として自社の取り組みを紹介しています。
前編となる本編では、猪股氏の発表内容を一部再編成してレポートします。
関数型×DDDを実践するためには、どんな考え方を用いるべきなのか? アプリケーション設計において重要なポイントとは? 本の内容をおさらいします。
- 関数型×DDDの方法論をまとめた書籍「関数型ドメインモデリング」
- 型を活用して、ドメインロジックを表現する方法
- 型でドメインロジックを書く際に、関数を使う方法
- I/Oは、オニオンアーキテクチャで端に寄せる
関数型×DDDの方法論をまとめた書籍「関数型ドメインモデリング」
猪股:私は「関数型ドメインモデリング」という本の翻訳者で、猪股健太郎といいます。よろしくお願いします。

猪股:今日は直也さんの発表に先立ち、この本の話を駆け足で紹介します。

猪股:この本には、「ドメインモデリングをしっかりやろう」「その際に関数型プログラミングのテクニックを使おう」という内容が盛り込まれています。本のサンプルプログラムは F# で書かれています。
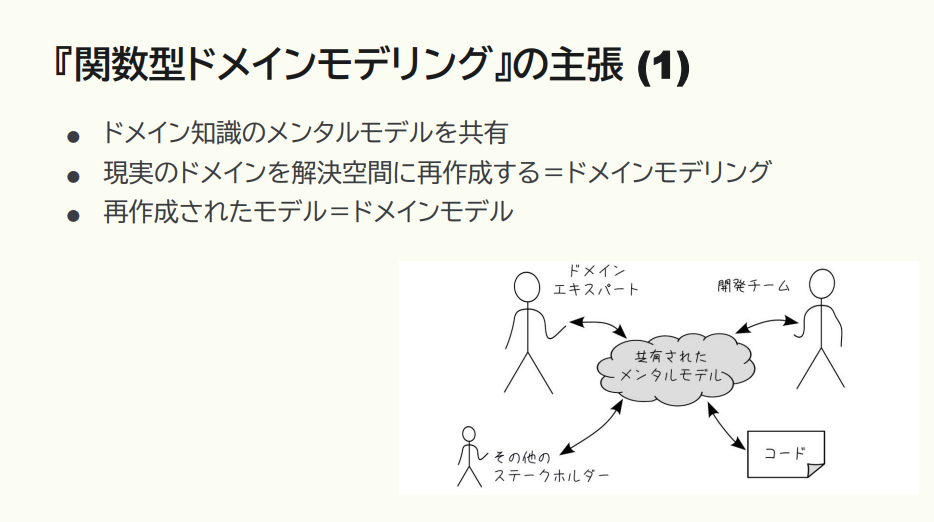
猪股:ドメインモデリングとは、ざっくり言うと「ドメインエキスパートと開発者の間で、ドメイン知識のモデリング(=ドメインの構造の整理)をして、同じメンタルモデル(ドメインの構造にまつわる概念)を共有しよう」という意味です。
さらにこの本では、以下3つの主張があります。
- ・ドメインエキスパートと齟齬なく会話をするために、ドメインモデルに特定技術を持ち込まない
- ・ドメインモデルとコードは差異がないように一致させる
- ・上記2つは、関数型プログラミングのテクニックで実現できる
では、本の内容を簡単に紹介します。
まず、この本で紹介する「ドメインモデル」とその実装方法について。
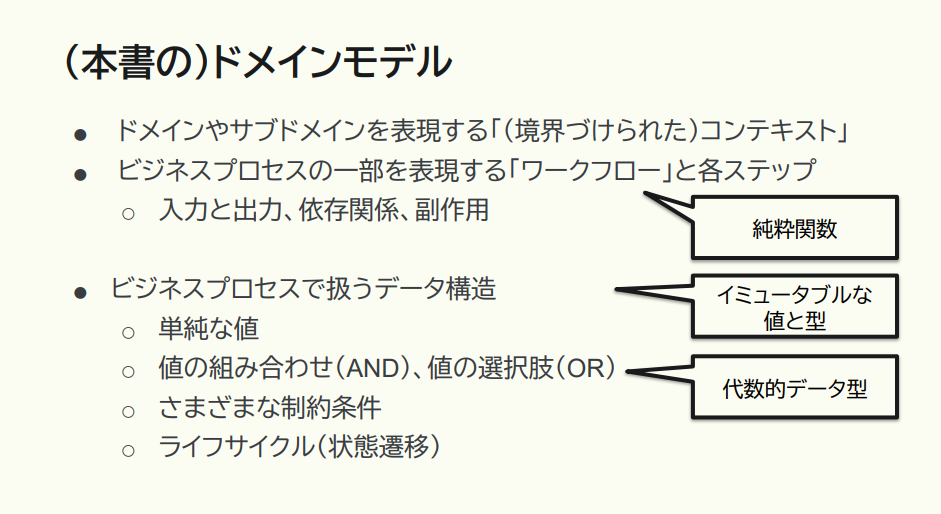
猪股:ドメインの中のロジック、つまりビジネスプロセスを表現するワークフローと、それを構成するステップは、純粋関数で表現できます。また、ビジネスプロセスで扱うデータ構造には、イミュータブルな型を使えます。なかでも AND や OR を表現するには代数的データ型を用いることができます。
サンプルコードが F# になっているのは、F#は静的型付けの関数型言語で、先ほどの代数的データ型なども表現できるよう用意されているためです。ただ、F# は非純粋関数型言語ではあるものの、本の中では純粋関数型のような活用方法を推奨しています。
F# での代数的データ型の表現の例として、スライドをご覧ください。

猪股:直積型、すなわち AND については、タプルやレコードが用意されていて、これらを用いて表現できます。レコードの方が名前をつけやすく、型の区別もしやすいのでおすすめです。
直和型、すなわち OR のほうは「判別共用体」として表現します。スライドのサンプルコード左側のように、じゃんけんでグーチョキパーを表現するという型であれば、それぞれの値にはデータは入りません。右側のように JSON のプリミティブを表現する場合は、色々な選択肢にそれぞれ個別のデータを格納できるようになっています。また、F#では、この判別共同体を使って、値が省略可能な Option 型や、エラーの可能性がある Result 型なども定義されています。
ほかにも、値が存在しない型や例外を表現する方法もありますが、特に例外は推奨されておらず、この本でも扱っていないため、詳しい解説は割愛します。
型を活用して、ドメインロジックを表現する方法
猪股:では、型を活用してドメインのロジックを表現するというのは、どういうことなのか。例として以下の Contact 型(連絡先型)で解説します。
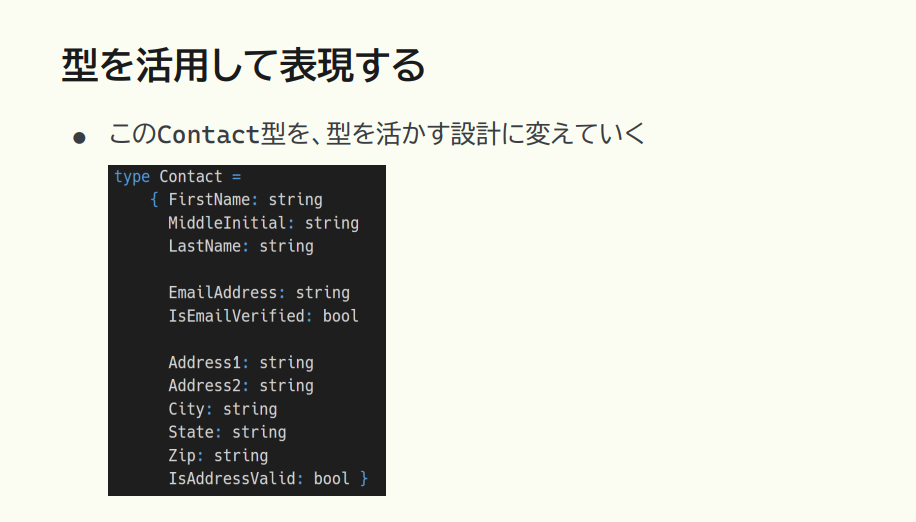
猪股:このサンプルコードでは、ロジックが表現されてるとは言えません。サンプルコードを上から見ていくと、一番上の First Name、Middle Initial、Last Name の塊は「名前」を表しているようですね。真ん中は Email Address とあるので電子メールの塊。下の方は郵便番号は住所などの塊。
これらの構造を整理して、それぞれ個別の型をつくっていくと、こうなります。
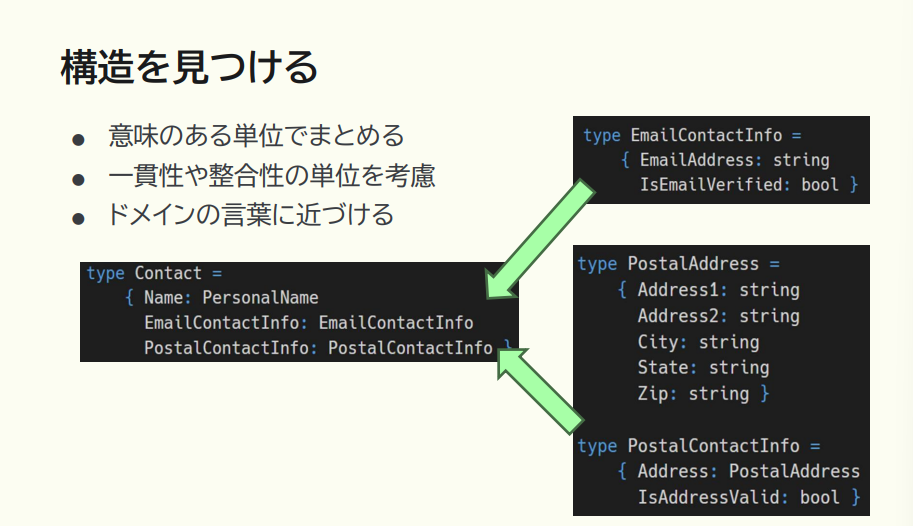
猪股:個別の型をつくるメリットは、つくった型が一貫性や整合性の単位になること、また、ドメインエキスパートと会話する時の言葉に近づきやすいこと。まずはこうした構造を見つけることが大切です。
また、単純な値でも、プリミティブ型は使わない方がいいです。これは関数型でなくてもよく言われる話ではありますが、型を個別に区別して定義しましょう。個別に定義することで型の混同を防ぎ、コンパイルでエラーを検出できるようになり、これが先ほどの「整合性」につながっていきます。
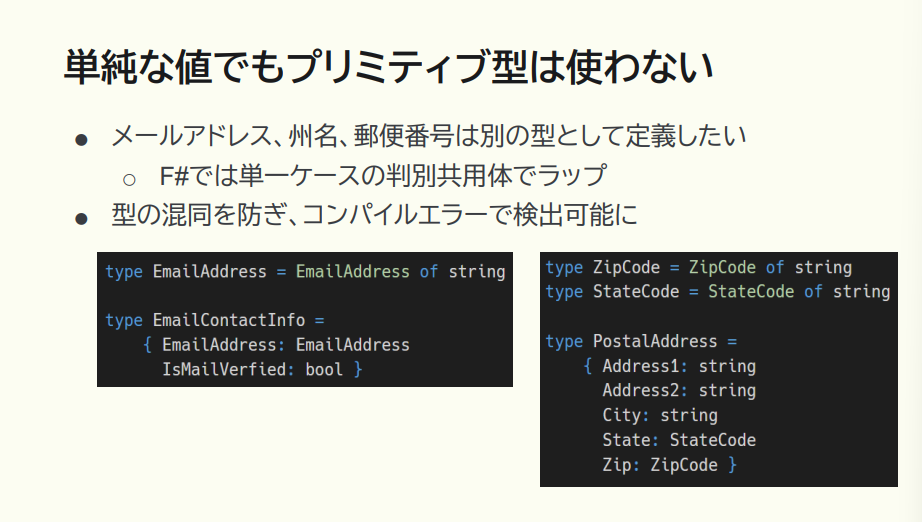
猪股:ほかにも、不正な状態を表現できないようにするために、代数的データ型でロジックを表現する方法の解説も、書籍に盛り込まれています。
例えば先ほどのサンプルコードに出てきた連絡先に、メールアドレスの部分と住所の部分がありましたが、「これらのどちらかが必要」というロジックをどう表現するのか。
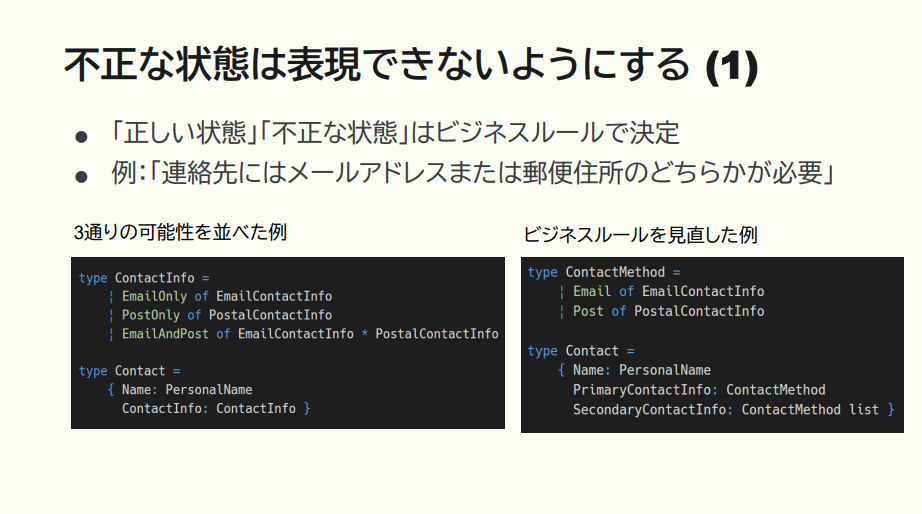
猪股:この場合、ビジネスルールをどのように捉えたかによって、モデリングの仕方が変わります。
例えばこの左側のサンプルコードでは、「メールアドレスと住所のどちらかが必要」を言い換え、「メールアドレスのみ OR 住所のみ OR 両方」の3通りのロジックがある、とモデリングしています。この場合は3通りの判別共用体がある、といった表現方法になっています。
対して右側のサンプルコードでは、「連絡手段としてメールと住所の2通りがある」「そのうち1つは必須、他は複数あってもいい」とモデリングしています。この場合の判別共同体は2通りですが、予備の連絡先をリスト型にすることで、0個以上の連絡先を表現しています。
あと先程少し話に出ましたが、個別の型をつくるメリットには「フォーマットチェックができる」という点も挙げられます。
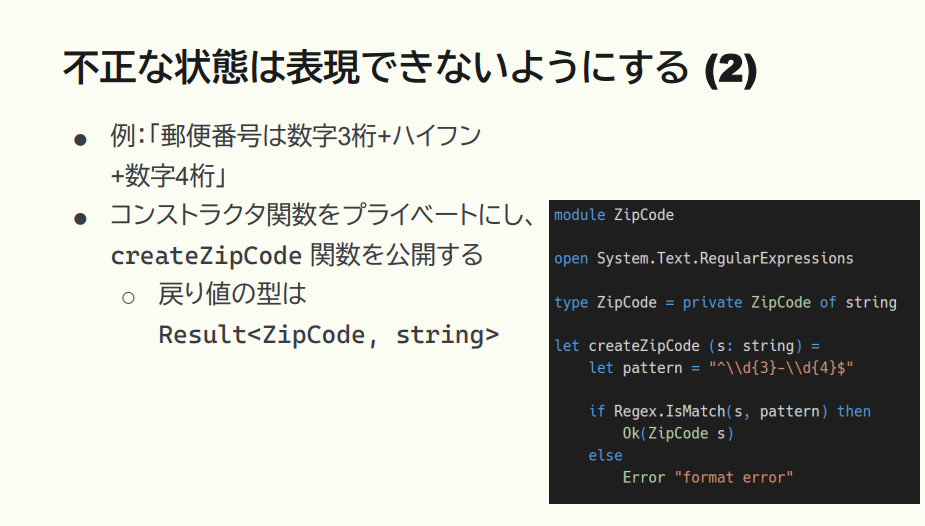
猪股:例えば郵便番号なら「数字3桁+ハイフン+数字4桁」のフォーマットがありますね。こうしたときは、フォーマットを必ずコンストラクタ関数をプライベートにしておいて、このフォーマットに合っているかチェックする関数(createZipCode)のみを公開するのです。チェックした際の「成功/失敗」の戻り値の型は Result で包まれます。
他にも、状態遷移を明示的に扱うよう意識してモデリングしましょう、という話もあります。
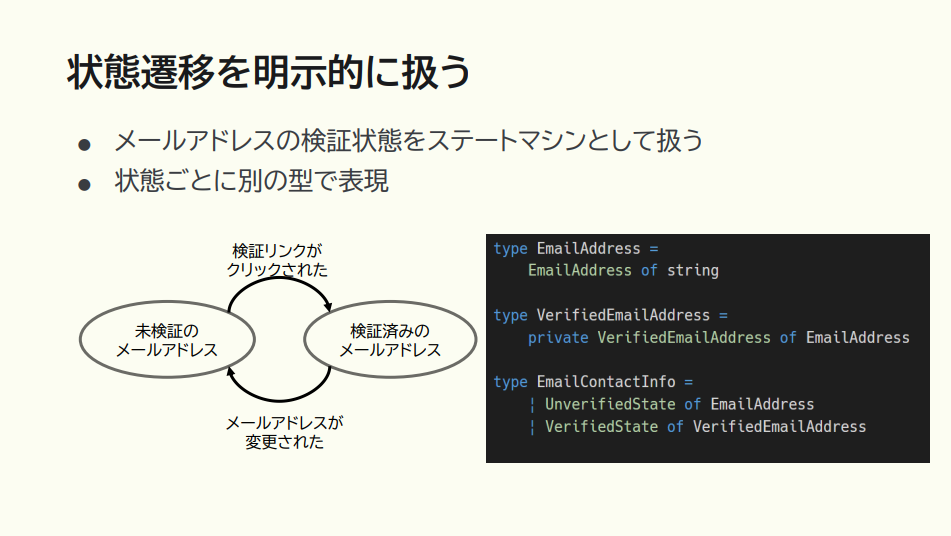
猪股:先ほどの Contact 型のサンプルコードの、Eメールの中に { IsAddressValid:bool } 、つまり bool フラグがありましたね。フラグが複数になると混乱の元になってしまうため、上記のサンプルコードのように、それぞれ別の型として表現した方がいい。すると、それぞれの型専用のロジックを定義していくこともできます。
あと、型は別々にしながらもそれらを一括して扱う場合は、先ほど言ったような OR、すなわち判別共用体を使っていくとよいでしょう。
他にも書籍では、ドメイン駆動設計の話にも少し触れています。

猪股:ドメイン駆動設計における「集約」という言葉は、永続化など一貫性の単位を表します。これを表現するには、結合が必ずしも密ではないところを見つけます。
疎結合にするために、このサンプルコードでは、注文(Order)の中に顧客情報を全部持たせるのではなく、識別子(ID)を介して顧客情報を参照するだけにしています。
ここまでが「型でドメインロジックを表現すること」に関する書籍の内容の紹介です。
型でドメインロジックを書く際に、関数を使う方法
猪股:続いて、型を使ってドメインロジックを書く際に、関数をどう使っていくのか、という話をします。
その際は、全体のドメインロジックの流れを「ワークフロー」として表し、その中にあるステップ同士を、関数合成でつなぎ合わせていく、というように考えていきます。
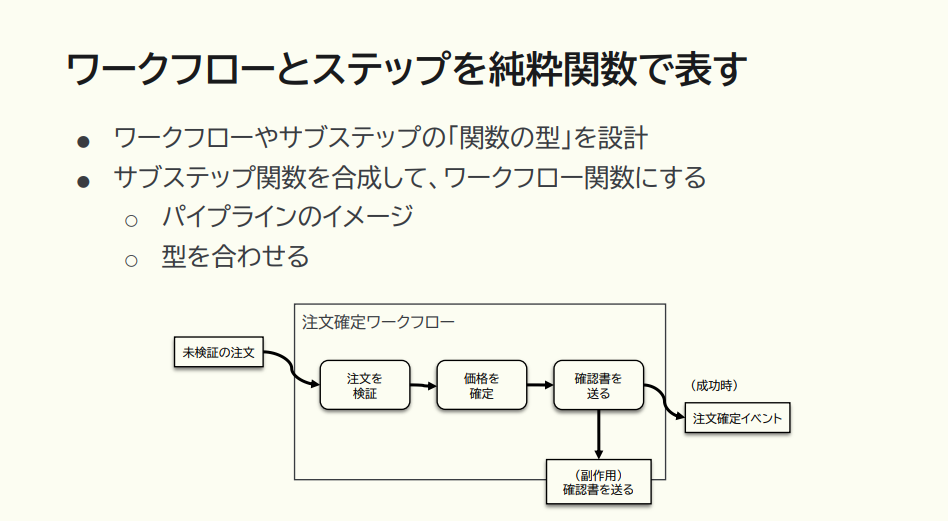
猪股:サブステップ関数がステップごとに変換されながら流れていくので、パイプラインのイメージを持つといいでしょう。ただ、型が合っていないと、ステップ同士が繋がらないために、うまく流れていきません。
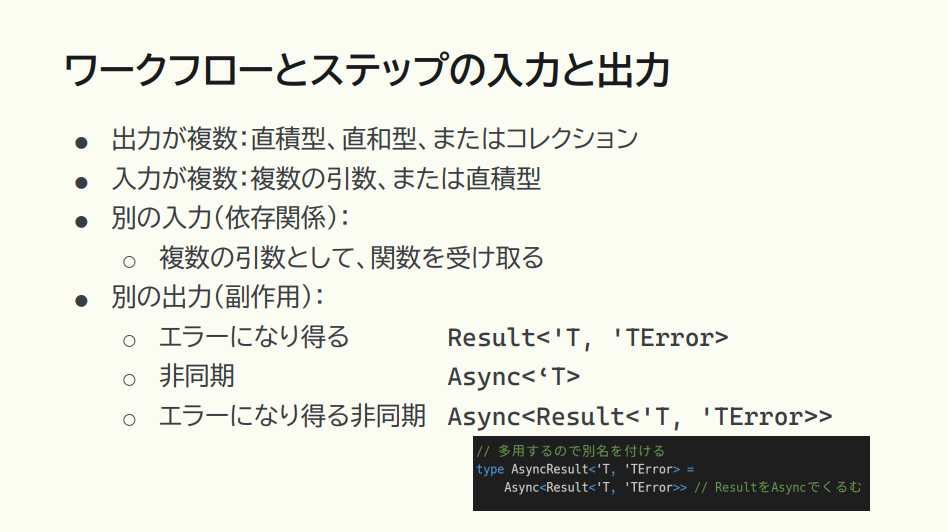
猪股:ステップ同士を繋ぐためには、関数に入力と出力が発生します。問題になりがちなのは、直接の入力と出力、つまりドメインオブジェクトの話ではなく、それに関連する別の入力と出力。
入力においては、いわゆる依存関係であり、複数の引数として依存物を受け取るときですね。出力においては、スライドでは副作用と表現していますが、エラーになりうるResult、非同期の場合のAsyncやその組み合わせが型として現れてきます。これを明示的に設計した上でどう構成するかが、考慮が必要なポイントになってきます。
では、注意点をクリアしながらステップ関数を合成し、ワークフロー関数をつくっていくためにはどうするか。

猪股:この例では、一番左の「注文を検証するステップ」である ValidateOrder で、未検証だった注文が検証されます。検証された Order を、今度は真ん中の「価格を確定するステップ」、PriceOrder で受け取って、価格が決定されます。これを一番右の「確認書を送るステップ」SendAcknowledgment が受け取って、顧客に確認書を送る。入力・出力の流れを見ていくと、ドメインオブジェクトは繋がっていますが、依存関係にはそれぞれのステップで違うものを持っています。
例えば、一番左のステップで、依存関係に CheckAddressExists とありますね。ここでチェックをする際に、先ほど解説した Result やエラーの対処などの副作用が生じると、それがその後のすべてのステップに引き継がれ、出力側に副作用が出てしまう。すると、入力側のドメインオブジェクトが合わなくなってくる。
こういう場合にどう考えていくべきか。まず入力については、部分適用するとよいでしょう。
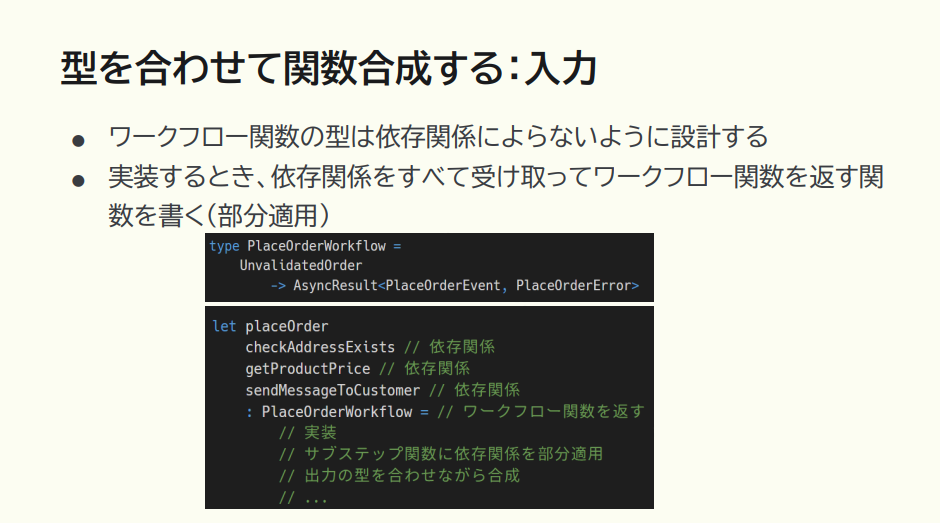
猪股:実装で関数合成をする際には、関数の中で使う依存関係を一旦全部受け取ります。そして、関数合成の前段階として部分適用する、つまりワークフロー関数を返すように関数を書くのです。すると、依存関係の部分は全部クリアされて、ドメインオブジェクトだけを受け取る関数になるから、次のステップとの関数合成が問題なくできるようになる。
では、出力に関してはどう考えていくか。一番分かりやすい Result 型の場合を例に挙げます。
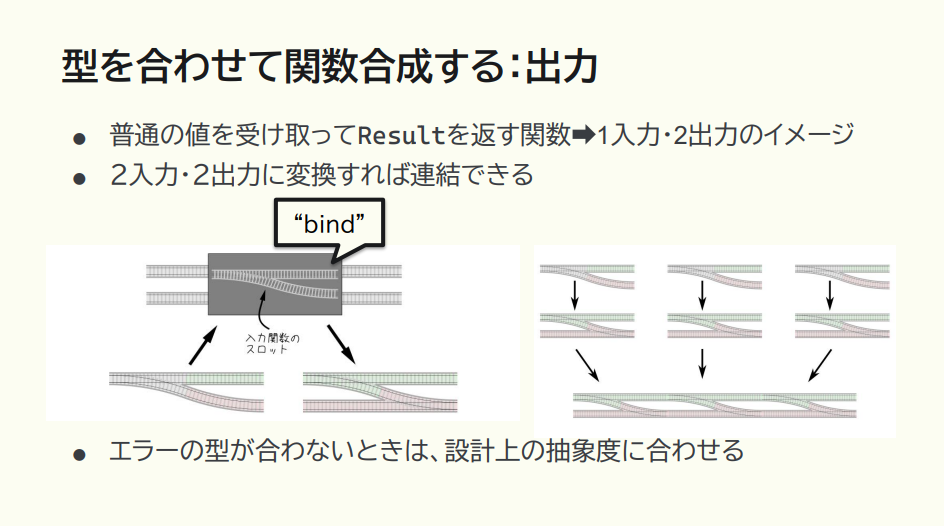
猪股:値を受け取って Result を返す際は、成功の場合と失敗の場合の2パターンが出力されます。つまり、1入力・2出力になるイメージです。その状態で次のステップに進もうとしても、次のドメインオブジェクトでは1入力を要求していますから、Result の出力が2になっていると繋がらない。
であれば変換関数を使って、2入力・2出力、つまり Result を受け取って Result を返す関数に変えればいい。これを bind といいます。
ただ、Result はジェネリック型なので、エラーのほうも型として内部的に持っていて、それが合わない場合もあります。そういう時はパイプラインの抽象度を改めて整理し、「その抽象度のエラー」という形になるように変換しましょう。そうするとエラーの型が合うようになります。
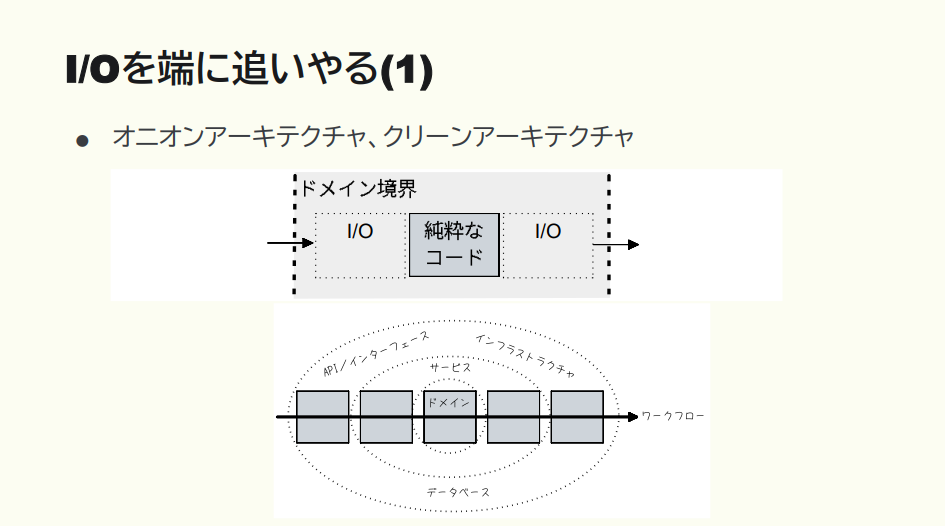
I/Oは、オニオンアーキテクチャで端に寄せる
猪股:次は、I/O をどう考えるか。この本では、オニオンアーキテクチャとしてドメイン境界の端っこに寄せるよう推奨しています。I/O は端っこで、真ん中は純粋な関数にしていく。
猪股:例えばDBの読み書きであれば、このように表せます。
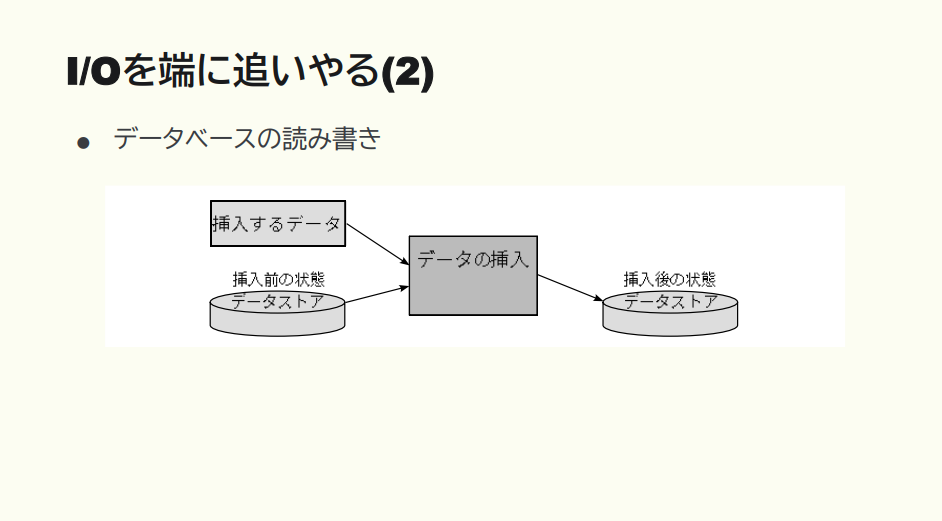
猪股:本体にあるロジックの関数ではデータの I/O には触らず、入り口の段で最初にデータから読み取って関数に渡す。関数の出力はそのあとデータに書き込む。このように書けば関数自体は I/O を考えなくてもいいのです。
Web API であればこんな感じ。
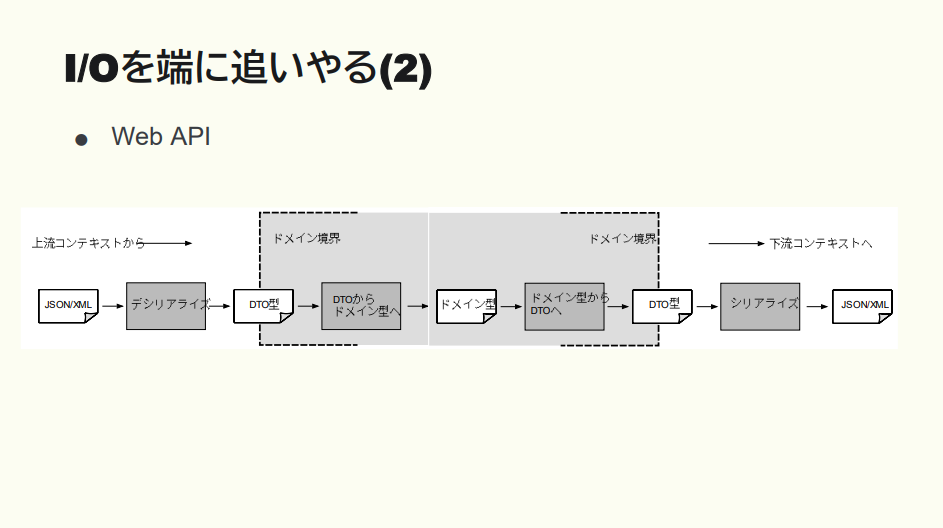
猪股:JSON での入力を受け取って変換するところはドメインの入り口で最初にやっておく。そして JSON で出力する際の、ドメインオブジェクトから DTO にしてまたシリアライズするのも、ドメインの端っこでやりましょう。
書籍「関数型ドメインモデリング」で紹介しているのは、ざっくりこのような内容です。後編では、これを使って一休ではどういうことをしたのかを、直也さんに解説いただきます。
執筆・撮影:光松 瞳
関連記事

【後編】TypeScript×関数型×DDDで、ユニットテストが激減。実践の全貌とTips【Open Developers Conference 2024 レポート】

ミノ駆動さんに「なぜ負債解消にDDD?」と聞いたら、ソフトウェア開発の本質に気づかされた

【t-wada】自動テストの「嘘」をなくし、望ましい比率に近づける方法【Developer eXperience Day 2024 レポート】
人気記事

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】

インデックスを張るだけでは足りない。数億件の名刺データを扱うSansanのSQLパフォーマンス改善

