![]()
最新記事公開時にプッシュ通知します
![]()
【t-wada】自動テストの「嘘」をなくし、望ましい比率に近づける方法【Developer eXperience Day 2024 レポート】
2024年8月8日


プログラマ、テスト駆動開発者
和田 卓人
学生時代にソフトウェア工学を学び、オブジェクト指向分析/設計に傾倒。執筆活動や講演、ハンズオンイベントなどを通じてテスト駆動開発を広めようと努力している。『プログラマが知るべき97のこと』(オライリージャパン、2010)監修。『SQLアンチパターン』(オライリージャパン、2013)監訳。『テスト駆動開発』(オーム社、2017)翻訳。『事業をエンジニアリングする技術者たち』(ラムダノート、2022)編者。テストライブラリ power-assert-js 作者。
日本CTO協会が主催する、開発者体験をテーマとしたイベント「Developer eXperience Day 2024」が、7月16日、17日に開催されました。
本レポートでは、7月16日に行われたt-wadaこと和田卓人氏のセッション「望ましい自動テストとは:どのようなテストが開発生産性と開発者体験を共に高めるのか」をご紹介します。
変化し続ける力を得るための自動テストとは、どんなテストなのか。それを整備し、維持していくためにとるべき戦略とは? 和田さんの知見が詰まった45分のセッションを、一部再編成してレポートします。
- 自動テストを書く目的は「変化し続ける力を得るため」
- 自動テストに生じうる2つの「嘘」が、テスト結果の信頼性を下げる
- テスト失敗時にとるべき2つの行動と、問題特定を助けるアサーションの書き方
- 「ユニット」「E2E」では定義がバラバラ 「テストサイズ」を使って明瞭に
- トロフィーもハニカムも、要はピラミッドと同じ。テストサイズのピラミッドを構築する
- アイスクリームコーンからピラミッドへ。テストサイズを下げるためには「テストダブル」
- 変化し続ける力を得るために、テストサイズのピラミッドを構築する戦略を立てよう
自動テストを書く目的は「変化し続ける力を得るため」
和田:今回は「開発生産性や開発者体験を高めるための自動テスト」について話します。
まず序論です。今回お話する自動テストとは、コードとテストを一緒に書きながら動かしていくという「自動でテストをしていく仕組み」のことを指します。
自動テストを書く目的は何でしょうか。ここで最初に、良かれと思ってドツボにハマるアンチパターンを挙げておきます。
それは、自動テスト、つまりテストの自動化を「コスト削減のためにやる」というアンチパターンです。このような目的の置き方をする現場はとても多いし、結果的にコストが削減される面も一部あります。しかし、コスト削減を目的にした場合、短期的には自動テストを書くための学習コストが、中長期的にはこれまで書いてきた自動テストの保守コストがのしかかってきます。すると「思ったよりもコスト削減効果がないね」という評価となり、手動テストに戻ってしまう。こういった現場を私はたくさん見てきました。
なぜ、このような目的を据えてしまうのでしょう? 私の知り合いのところてんさんが、その理由を捉えたポストを投稿していたので、紹介します。
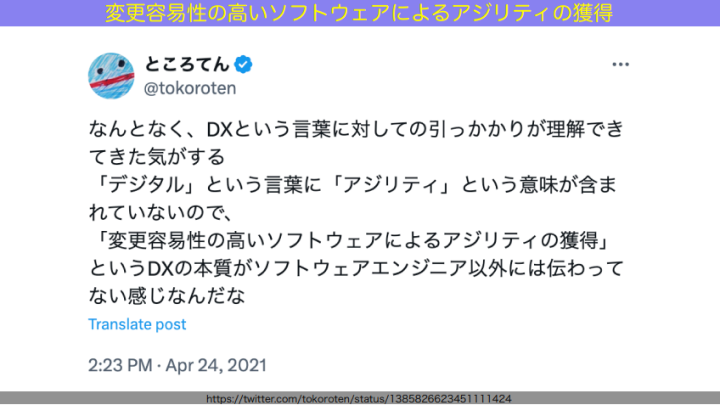
和田:これはとても良いポストだなと思っています。いわゆるデジタルトランスフォーメーションを指す「DX」のD、デジタルという言葉には、「アジリティ」という意味が含まれていません。そのため、DXの本質である「ソフトウェアを変更容易性の高い状態にして、社会の変化に応じてソフトウェアを変化させながらついていく」という意味合いが、DXを目指す人々に伝わりきっていない。
だから、自動テストを書く目的が、本来DXの中で目指すべき「変更容易性の高いソフトウェアをつくること」ではなく、「コスト削減」などDX以前の価値観を反映したものになってしまうのだと思います。
DXを実現したいなら、変化についていく、つまり変化を可能にすることが、とてもとても大事です。自動テストも、変化を可能にしていくための大事な技術・プラクティスの1つである、と考えています。
では、「自動テストを書く目的」はどう据えるべきなのでしょうか?ここまでの話を、次のページにまとめておきました。

和田:これをもう少し詳しく表現すると、次のページ。

和田:信頼性の高い実行結果に、短い結果で到達する状態を保つことで、開発者に根拠ある自信を与え、ソフトウェアの成長を持続可能にすること。これが私が考える、自動テストの目的です。
自動テストに生じうる2つの「嘘」が、テスト結果の信頼性を下げる
和田:では、この目的を果たせる自動テストを、どうやって書いていけばよいのか。
先ほど示した「自動テストの目的」を分解すると、今日のアジェンダになります。

和田:まず1つ目、信頼性の高い自動テストとは何か。書籍『LeanとDevOpsの科学』から紐解いていきましょう。この本は必読書と言っていいですね。
65ページ目に、こんなことが書かれています。

和田:テストの自動化において、ITパフォーマンス、つまり企業の予測尺度として統計的に優位な形で影響があった要素は次の2つ。
- ①信頼性の高い自動テストを備えること
- ②開発者主体で受け入れテストを作成・管理し、手元の開発環境で簡単に再現・修正できること
今日はこの中の「①信頼性の高い自動テストを備えること」にフォーカスします。
信頼性の高い自動テストとは、ざっくり言うと、テストの結果に「嘘がないこと」です。嘘がないから信じられる。自動テストの結果を信じることができれば、自分たちのコードを「テスト成功→リリースやデプロイOK」「テスト失敗→コードに直すべき場所がある」という2択の状態に制限することができます。これが、開発生産性も開発者体験も高い状態、といえるわけです。
自動テストに生じうる「嘘」は2つあります。

和田:1つ目は「偽陽性(false positive)」。火災報知器に例えるなら、火が出ていないのに火災報知器が鳴るような状況です。自動テストにおいては、コードは悪くないのにテストが失敗する状況のことを指します。コードは全く悪くないのに、単に実行が不安定とか遅いとか何らかの状況によって、テストが成功したり失敗したりと不安定になってしまう。すると、狼少年みたいになって信じなくなってしまう。
2つ目は「偽陰性(false negative)」。火が出ているのに火災報知器が鳴らない。コードにバグがあるのに、テストが失敗しないという状況です。
図にまとめるとこうなります。

和田:この2つが多いと、テストの結果に対して疑心暗鬼になってしまい「成功すればデプロイ、失敗すればコード修正」の2択に持ち込めなくなってしまう。そうならないように、これらの「嘘」を減らして信頼性を獲得・維持しなくてはなりません。すると開発生産性も、開発者体験も向上し、変化に強いソフトウェアをつくることができます。コストはかなりかかり続けますが、それだけの価値があります。
では「嘘」をどうやってなくしていくべきか。まず、偽陽性と偽陰性の典型的なパターンを紹介します。

和田:偽陽性は、大きく分けると「脆いテスト(brittle test , fragile test)」と「信頼不能テスト(flaky test)」の2つに分けられます。
先に、特に有名な2つ目「信頼不能テスト」について説明します。
信頼不能テストとは、コード(プロダクトコード/テストコード問わず)に一切手を触れなくても、結果が成功だったり失敗だったりと不安定なものを指します。これはE2Eテスト、例えばテストコードからブラウザを自動で動かして、画面遷移しながらボタンをクリックして…といったものによくありますね。
信頼不能テストがたくさん出てくると、テスト失敗に対して鈍感になっていき、失敗時に「もう1回リトライすれば多分動くはず」と、成功するまでリトライを繰り返すといった運用になってしまいます。
この信頼不能テストはどれくらいまで減らすべきか。書籍『Googleのソフトウェアエンジニアリング』では「テストスイート全体の1%が信頼不能テストになると、エンジニアはテストの結果を信じなくなり始める」とされています。
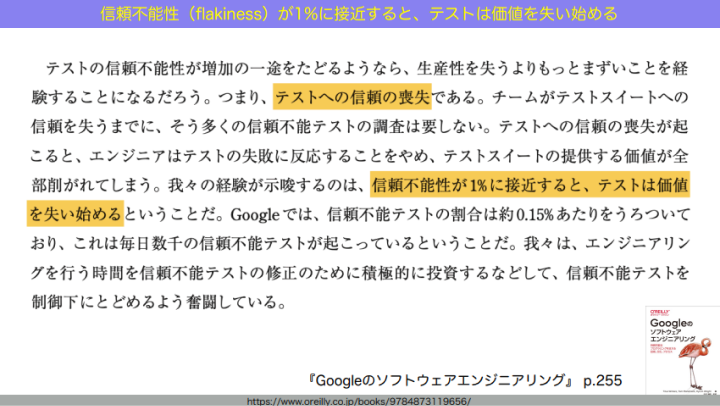
和田:これを可能な限り減らすために、運用レベルでは、信頼不能テストであるとわかった時点で flaky というタグをつけて隔離します。メインのCIラインとは別のところで動かしておき、安定して動くようになったら flaky タグを外してメインに戻します。
もう1つの脆いテストとは、手を触れるとすぐに失敗するテストのことです。mock だらけのテストとか、プライベートメソッドに思いきり触れてしまっているテストとか。外から見た振る舞いは全く変わらないのに、実装の中身をちょっと変えたら、なぜかテストがバンバン失敗し始める。テストと実装の構造的結合度が高すぎたり、不必要に詳細までテストをしてしまっていたりすると、こういうことが起こってしまいます。
次は、偽陰性。バグがあるのにテストが成功してしまう状況ですね。

和田:1つ目、最もベタな偽陰性は「空振り」です。テストを動かしていると思ったらスキップしてました、みたいなパターンですね。現場レベルでは最もよくあるのが、開発中に「テストをスキップする」というメソッド(例:disable annotation、skip など)をつけていて、そのままコミットしてしまい、テストが全て通ったと思ったらそもそも動いてなかった…というパターンです。
2つ目はカバレッジ不足とテスト不足。カバレッジ不足とは、書かれるべきテストが書かれていないことです。テストすべき行にテストがなければ、その行にバグがあっても、テストが成功してしまいますよね。これはコードカバレッジツールを通して可視化し、倒すことができます。
手強いのはテスト不足です。これは、書かれるべきコードが書かれていない状態です。コードが書かれていない、つまり人間の仕様レベルで把握できていない時には、コードが書かれていないからテストももちろん書かれていない。このためテスト全体は通ってしまいます。人間が把握できていない。こいつがラスボスです。
3つ目は「自作自演」。テストとコードが自作自演の関係になってしまっている、という状況です。
例を挙げます。JavaScriptで書いたサンプルコードです。画面上半分がテスト対象のプロダクトコード、下半分がテストコード。このプロダクトコードは、商品の価格の中から税額だけを返すメソッドです。
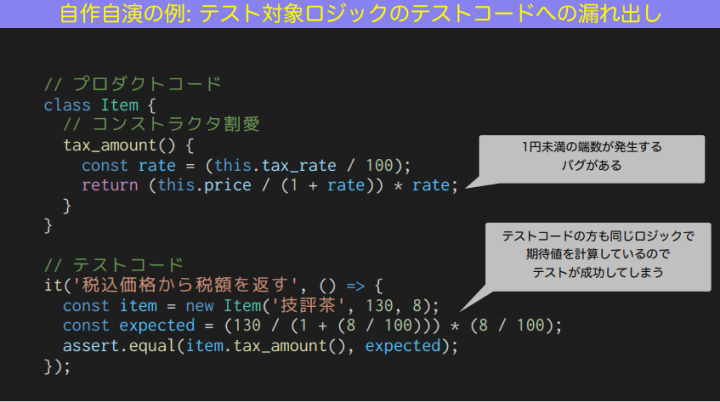
和田:このテストは成功しますが、プロダクトコードにはバグがあります。
JavaScriptのNumber型は、浮動小数点数なので、端数が出ます。1円未満の端数というバグが出る。でもこのテストは成功しちゃう。なぜか? プロダクトコードの方の期待値も、同じ計算式で計算しているからです。
このような「プロダクトコードで望む振る舞いを、テストコードで再現しており、テストになっていない」というパターンは、現場で本当によくあるので、テストコードを書く際に注意すべきポイントです。
テスト失敗時にとるべき2つの行動と、問題特定を助けるアサーションの書き方
和田:続いて、アジェンダ2つ目「実行結果」の話をしましょう。

和田:私は、自動テストの実行結果は単なるデータではなく、情報、つまりそれを見た人間に意思決定と行動を促すものであってほしいと思っています。
では、テストの実行結果を見た人間は何をするべきか。先述の「テストの結果に嘘がなければ、成功ならデプロイ、失敗なら修正、の2択に収束していく」という話につながります。テスト結果とそれに応じた人間の行動は、この図のように落ち着いていくわけです。

和田:ただ、実は自動テストの失敗には2種類あり、失敗した時にとるべき行動がそれぞれ若干異なります。
1つ目が、Execution Error。自動テストの実行中に、プロダクトコードのどこかから発生する、実行時のエラーのことです。例えば、null pointer exception などですね。これが起こった際は、コードのどこで失敗したかを stack trace などから探しに行って、何が起こったかを推測していきます。
2つ目が、Assertion Failure。テストコードの結果のアサーションで失敗するものを指します。自動テストを書いて、テスト対象を動かし、結果が返ってくる。この結果は期待値と一致するかな?とアサーションを行おうとするときに失敗するのです。このとき「テスト対象は問題なく動いているけど、結果が期待と違う」という現象が起きます。テスト対象の動き自体に問題はない以上、原因を特定する難易度が若干高いです。
となると、失敗した時に助けになるアサーションを書かなくてはなりません。
試しに悪い例として、頼りにならないアサーションを書いてみました。これは軽減税率のロジックだと思ってください。レシートの税額欄のところに、reduced だから軽減税額の合計が40であること、というようなアサーションをテストの方で書いています。
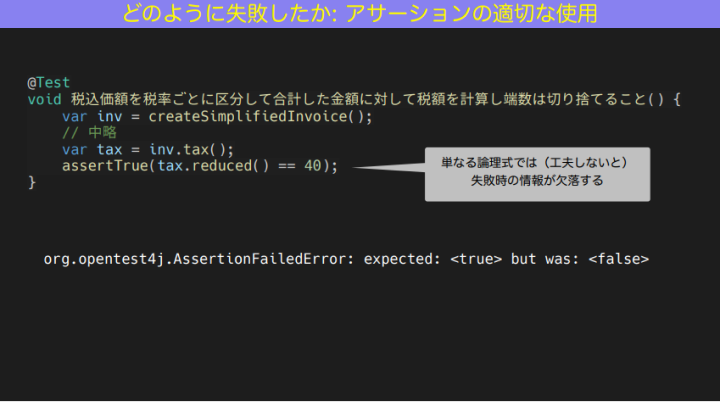
和田:テストコードは単なる論理式で書いています。assertTrue で reduced が 40 。
この場合の問題点は、Assertion Failed Error に「true だと思ったらfalse でした」ぐらいの情報量しかないこと。これでは、次の一歩が難易度高いんですよね。エラーが起こったとき、どのような値が出力されたのかわからない。だから、何からどう調べていいかわからなくなってしまう。
でも値が分かれば、このサンプルコードの場合、例えば40を期待していたけど返ってきたのは39だったときは「1ズレてるということは、もしかしたら切り捨てのロジックの誤りだな」、nullだったときは「そもそも inv に値がきているのか?」など、出力された値によって、調べるべきところのアタリをつけることができます。
修正すると、こんな感じになります。
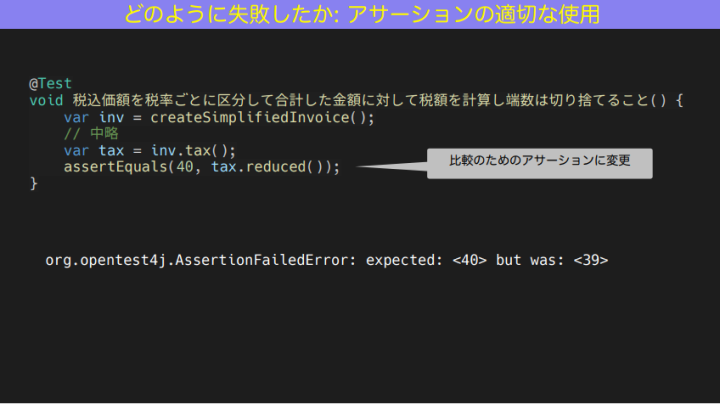
和田:このような場合、テストが成功しているときは、危うさに気づかないんです。失敗して初めて「こいつ頼りにならないな」と気づくので、Assertion Failureが起きた際も返ってきた値を確かめられるように、最初からちゃんと書いておきましょう。こういう細かいところで、生産性に差が出てきます。
「ユニット」「E2E」では定義がバラバラ 「テストサイズ」を使って明瞭に
和田:次に、アジェンダ3つ目「短い時間で到達する」に行きましょう。

和田:信頼性の高い実行結果に「短い時間で到達する」ためにどんなテストを書くべきか?これを明らかにするために、いわゆるテストピラミッドのようなフレームワークを使います。
まずは、テストピラミッドにおいてよく使われる「ユニットテスト」という言葉について、皆さんの捉え方を教えてください。この5問、それぞれどう思いますか?
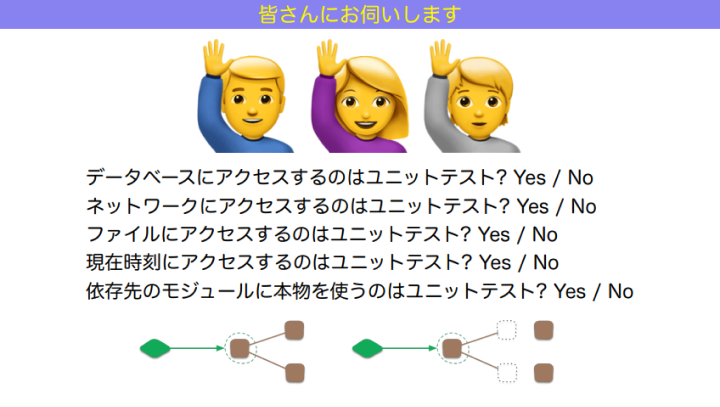
和田:ここで問いたいのは「あなたにとって、また、あなたのチームにとって、ユニットテストとは何ですか?」ということです。正解はありませんし、どこで聞いても答えはバラバラになります。
つまり、ユニットテストという言葉の認識が人によって異なり、合意が取れていないんです。先ほどの5問に関しては、人によって考え方が異なるものを集めています。例えば5つ目の「依存先のモジュールに本物を使うべきか」。本物を使えるならその方がいいと思う流派もあれば、偽物を使うことによってこそ正しくテストができると思う流派もあります。このように、2つの考え方が生まれ、どちらも栄えた結果、人によって見解が異なる部分が生まれてきました。となると、「チームでユニットテストを書いていきましょう」と言っても、メンバーそれぞれがバラバラの方向に進んでいってしまいますよね。
テストの整備をするために「どんなテストを、どこまで、どうやって書くのか」を議論したくても、こうした「人によって考え方が違う言葉」を使って話すと、議論がすれ違ってしまいます。
もっと明解で、かつ開発生産性やCIの速さ、開発のリードタイムやスループットなどに直接影響を及ぼすような基準はないのでしょうか。
そこで「テストサイズ」という分類を使ってみてはどうか、と私は考えています。
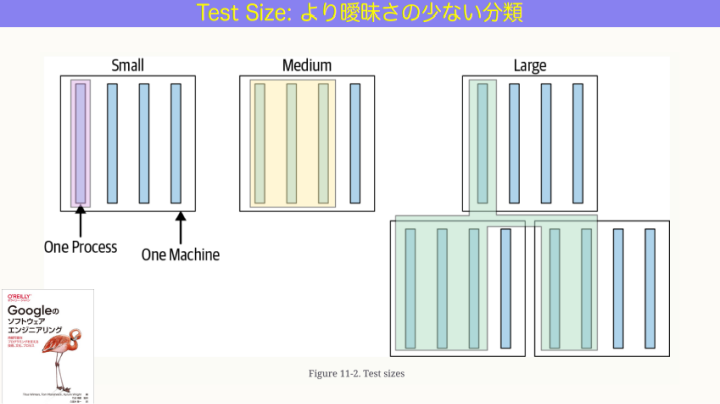
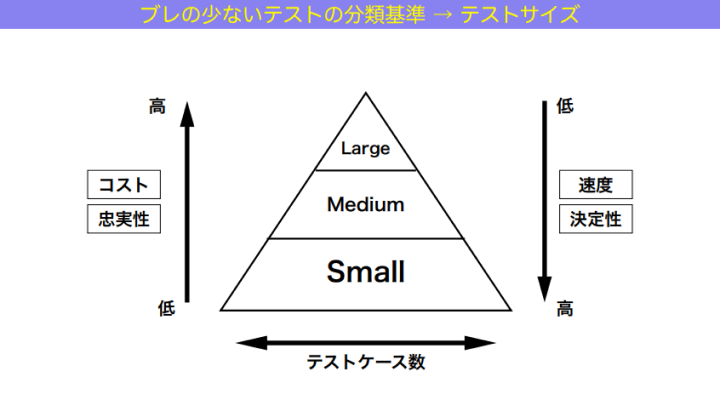
和田:テストには「サイズ」があります。スモール、ミディアム、ラージ。
スモールテストは、テストの実行が1つのプロセスに収まっているもののこと。ミディアムテストは、1つのプロセスに収まっていないけど1つのマシンに収まっているもの。そしてラージテストは、1つのマシンにも収まっていないもの。
この3つは明確で、曖昧さのない定義です。
ちなみに、ミディアムテストという分類は結構応用が利きます。例えば Docker Compose などでデータベースのコンテナを立て、selenium のブラウザのコンテナを立て、テスト対象のサーバーのコンテナを立てても、1マシンに収まってるから「ミディアム」です。つまりミディアムであれば、無理なくCIに乗るんです。GitHub Actions でも Circle CI でも、ミディアムでガンガン回せます。ラージはそういうわけにはいかないから、ここの分かれ目で分類されているのです。
こうした分類の背景には「ネットワークアクセスを狭める」という意図があります。なぜなら、ネットワークアクセスは一番遅くて不安定だから、テストの安定性や速度に最も影響を与えますし、テスト結果も flaky になりやすい。であれば、ネットワークアクセスを狭めていけば、テストは速く、安定していくといえます。狭めていく時に、スモール、ミディアム、ラージと、サイズを表す語彙を使うと、定義が明快になっていきますね。
例えば、GoogleのAndroid開発チームにおけるテストサイズ運用はこんな感じになっています。
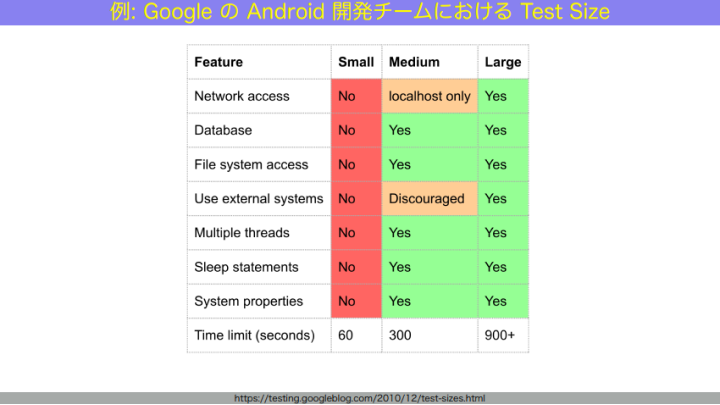
和田:スモールテストはネットワークにも、データベースにもファイルにもアクセスしない、Noが並んでいますね。すると、ものすごく速く安定して動きます。
ミディアムテストは、ローカルホストであればネットワークと繋げます。データベースもファイルシステムも繋いでよし。外部システムは推奨しない。スモールテストよりテストできる範囲が広くなる代わりに、ちょっと遅くなります。
ラージテストは全て本物を使いますが、その代わりにテスト結果が出るまでが遅く、実行自体も不安定です。
これらのテストサイズのスモール、ミディアム、ラージは、我々がよく言うものの定義がはっきりしていなかったユニットテスト、インテグレーションテスト、E2Eテストと、3×3の関係で表すことができます。後者は便宜上、テストの範囲、つまり「テストスコープ」としました。各マスの中には、私個人の意見を記載しています。おすすめ度のようなものだと捉えてください。
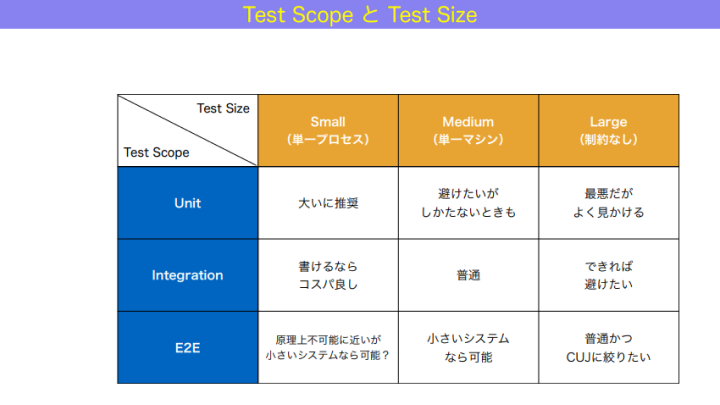
和田:この中で比較的おすすめ度を高くしている、左上から右下にかけての斜めのラインが、テストを整備する上での基本的なラインとなります。
ユニットテストはなるべく単一プロセスで動いてほしい。インテグレーションテストは単一マシンでコンテナ化して動けるようになってほしい。E2Eテストは、ユーザーの実際の操作と同じようなレベルの抽象度で実際のシステムを動かすので、ラージテストとなります。ただ、ここで頑張りすぎるのではなく、CUJ(クリティカルユーザージャーニー:超正常系)になるべく絞っていきたい。
となると、この中心の斜めラインを基準に、コスパの良し悪しを測ることができるようになります。
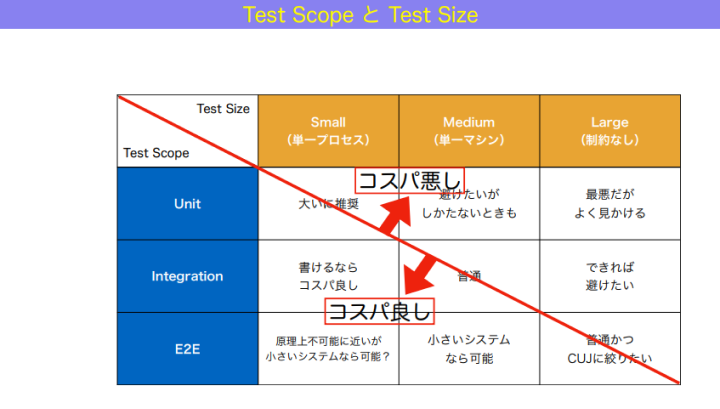
和田:図で示したように、右上に寄れば寄るほどコスパが悪くなっていきます。ここで「コスパ」と表現しているのは、投資対効果が低い、あるいは書いても助けにならないとか、足手まといになっちゃう、という意味合いです。
左下に寄るほど、書くとかなりお得。右上にあるものよりも、同じテストでもカバー範囲が広く、速度が速く、安定しているからです。例えば左下の「E2Eかつスモール」は、原理上不可能に近いものの、小さいシステムならできるかもしれません。
ちなみに「ユニットかつラージ」はコスパが最悪なのですが、なぜかよく見かけるんですよね。ラージということは、実システムを使い、かつ外部のネットワークアクセスもある状態。でもテストしているのは、ユニット相当のもの。具体例は、E2Eテストのツールを使って画面のバリデーションロジックとかを網羅的にテストしているような状況を指します。こういったテストを行っても、ラージだから遅くて不安定で、結果的には flaky test が多くなり、テスト結果を信じられなくなってしまいます。これは、ふさわしくない道具を使って網羅的にテストしようとしているといえるため、コスパが良いとは言えません。
トロフィーもハニカムも、要はピラミッドと同じ。テストサイズのピラミッドを構築する
和田:では、信頼性の高い実行結果に短い時間で到達する状態を、どうやって状態を保っていくべきか。良い状態を保つとはすなわち、望ましいテストの比率を維持すること。
では、望ましいテストの比率とはそもそもどういったものなのか?を話していきます。

和田:ここでも出てくるのが有名な「テストピラミッド」。これは、自動テストの信頼性を中長期的に保つために最適なバランスを、ピラミッド型で示したものです。
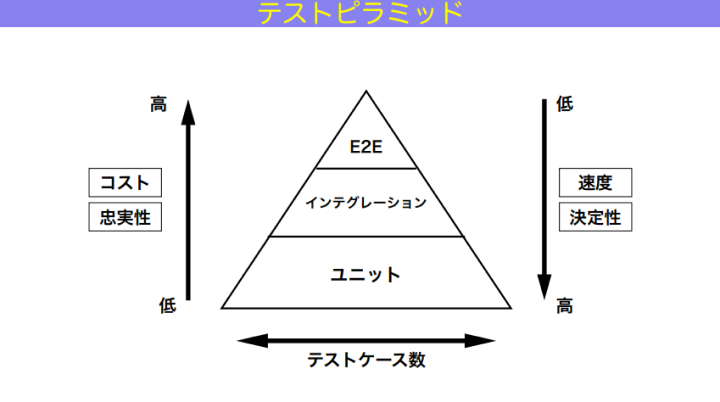
和田:図の上部から、E2Eテスト、インテグレーションテスト、ユニットテストがあって。ユニットテストをたくさん用意して、全体を支えるべきである。真ん中のインテグレーションテストはもうちょっと数が少なくて、その上のE2Eテストが一番少ない。
左側の縦軸で上に行くほど高いと示されているのは、コストと忠実性です。忠実性とはつまり「本物っぽさ」。最も忠実性の高いE2Eテストは、本物のインフラ、本物のシステムを使うので、一番本物っぽい。逆に忠実性が最も低いユニットテストは、mock や stub など偽物を使うし、開発者の妄想も混ざる。だから忠実性、つまり本物っぽさは一番低い。その代わり右側の縦軸にある、速度も、決定性すなわち結果の安定度も一番高いです。
図の上部にあるテストほど、スピードが遅くなり安定度も下がる。すると、コードが悪いのとは別の理由によって失敗したりするようになるわけです。そしてテストピラミッドでは、これらの要素の高低問わず、どの種類のテストも書くべきとされています。
このテストピラミッドのモデルは、2003年ごろにマイク・コーンが提唱したと言われています。明らかなアンチパターンである「アイスクリームコーン型」と対比して説明されることが多いですね。
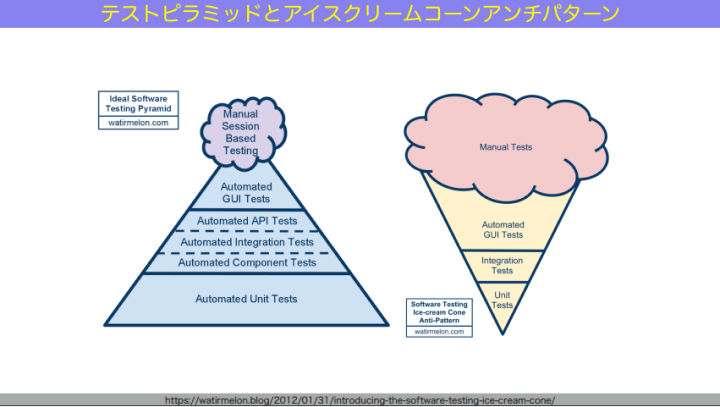
和田:アイスクリームコーン型では、図の下から見ていくと、ユニットテストが大幅に少なくて、その1つ上のインテグレーションテストも少ない。その上にある「Automated GUI Tests」つまり画面を使った自動テストが全体を支えていて、それよりもさらに大量の「Manual Tests」、人間が手と目で1つ1つテストしている状態を指します。この比率がアンチパターンであり、なんならアイスクリームのコーンがなく、アイス部分(Manual Tests)しかないみたいな組織もいっぱいあったりするわけです。
これらがよく議論に上り続けてきた「テストピラミッド」と「アイスクリームコーン型」です。しかし昨今では、テストピラミッドは今から20年前のモデルなので、「もう古いのでははないか」といった議論も出てきています。
例えば、図の左側のような「トロフィー型」のテスティングトロフィーというモデル、あとは右側のような、「ハチの巣型」のテストハニカム。これらのモデルが、現代のソフトウェア開発に合うのではないか?と提唱されています。この2つの共通点は、テストピラミッドと比べて「インテグレーションを分厚くしましょう」という提案をしていることにあります。
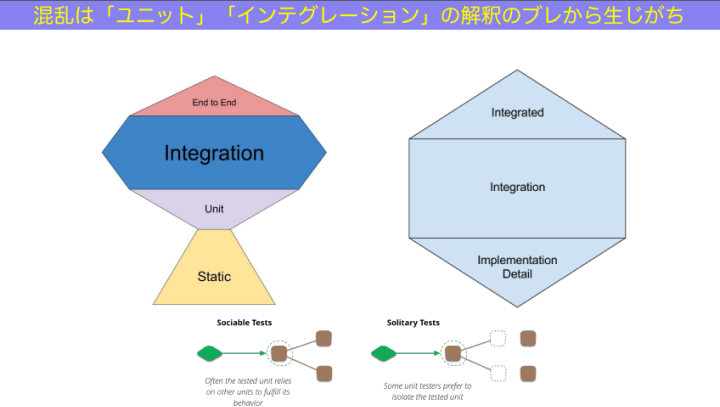
和田:でも一般開発者である我々は、何を基準にするべきかと混乱してしまいます。「テストピラミッドを信じてやっていこうと思ったら、もう古いとか言われていて、時代はトロフィーだ、ハニカムだ、というけれど、結局どうしたらいいのかわからない…」と。
この混乱の原因も、先述の「ユニットテスト/インテグレーションテスト/E2Eテストなどといった言葉の定義がはっきりしていないこと」なのです。ハニカムもトロフィーもピラミッドも全部、このブレブレの軸に沿って「どのモデルがいいか」と議論している。だから、結局どのモデルがどう優れているのか、はっきりした結論が出ないのです。
もっとブレの少ない定義って、なかったっけ?……ありますよね。今日アジェンダ3つ目で話した「テストサイズ」です。ということで、テストサイズの定義を使って、テストピラミッドのモデルを表現し直してみたものがこちらです。
和田:先ほど話題に出たトロフィー型における「Unit」「Static」、ハニカム型における「Implemetation Detail」はもちろんですが、それらにおける「Integration」の多くも、テストサイズで表したピラミッドにおける「Small Test」のことを言っていたんです。
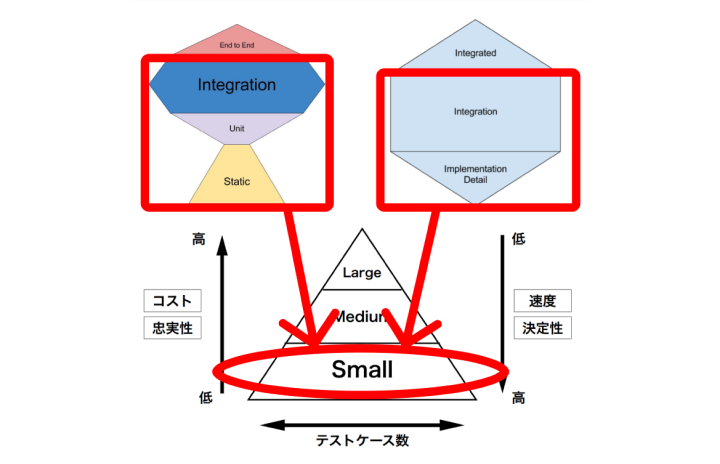
和田:つまり、トロフィー型やハニカム型など、新しく生まれたテストのモデルは、「ユニットテスト」「インテグレーションテスト」などといった基準に対する解釈のブレで生まれたものであり、テストサイズの観点から並べ直してみると、どれもおおむねピラミッド状に近づいていく、と言えます。ですから私は、テストサイズの定義を使ったテストピラミッドを構築していくと、望ましいテストの比率を実現することができる、と考えています。
そしてこれができると、ビルドパイプラインも最適化することができます。
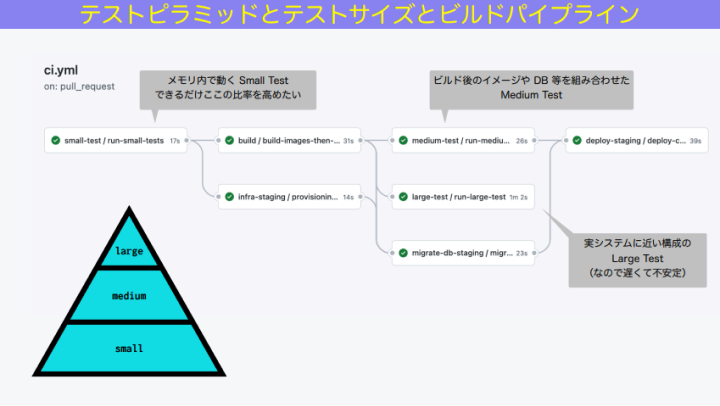
和田:この図のように、スモールテスト、ミディアムテスト、ラージテストの順に動くよう、ビルドパイプラインを整備していくのです。
例えばディレクトリ名やタグ付けなどでスモールテストだけ最初に動かします。これはあっという間に動きます。スモールテストが失敗したら、もう打ち切りでいい。スモールテストが成功したら、imageのビルドを始めてミディアムテストを動かす。ラージテストは不安定なので最後に動かす。なんならビルドパイプラインから外して、別途スケジューラで動かしておくと、運用としては安定しますね。これがビルドのスループットそのものを高めることに繋がっていきます。
テストサイズの定義を使ったテストピラミッドの整備は、何を整備すべきかといった定義がはっきりするのはもちろん、こうしてビルドパイプラインの最適化にも役立つのです。
アイスクリームコーンからピラミッドへ。テストサイズを下げるためには「テストダブル」
和田:ではどうやって、テストサイズの定義を使ったテストピラミッドをつくっていきましょうか。多くの現場では、最初はアイスクリームコーン型から始まります。
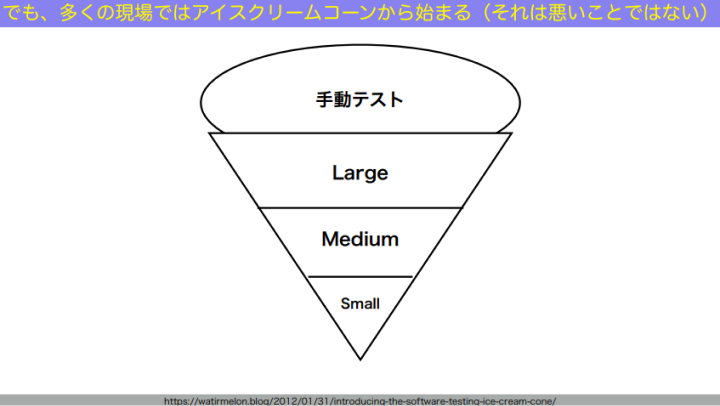
和田:でも、別にそれは悪いことじゃありません。「テスト容易性とは何か」を理解していないと、最初からピラミッドをつくっていくことはできませんから。最初は手動テストから始めて、E2Eテストとかのツールを入れて、テスト自動化してみたいなところから始まるんですよね。問題は、これがそのまま長続きしてしまうことです。アイスクリームコーン型がずっと続くと、図の上部ほど不安定で、開発を助けるテストじゃなくなってしまうから、つらくなってくる。
ではなぜ、アイスクリームコーン型になってしまうんだろうか? 実は、良かれと思ってこの形になり、それが続いていってしまうことが多いのです。これは構造的な問題です。
例えば、開発チームとQAチームが分かれていて、QAチームが自動テストを書いている、という組織でよく起こることを挙げましょう。QAチームがテスト自動化率を高めていこうとすると、そこで使う道具が例えばUIを経由したE2Eのテストツールだったりします。すると全体のテスト自動化率は上がっていくんだけど、その中で書かれる自動テストは全部ラージテストになってしまう。良かれと思って、どんどんドツボにはまっていってしまうということになるんです。
QAチームが自分たちの範囲内でベストを尽くそうとすると、むしろ全体としては悪い方向に行ってしまう。アンチパターンっていうのは悪しかれと思ってやるんじゃなくて、良かれと思ってドツボにはまっていくからアンチパターンなんですよね。
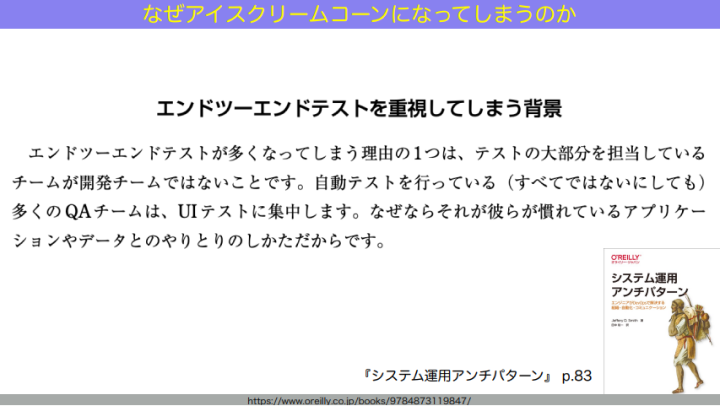
和田:テスト自動化を担うチームと開発チームが分かれていることと、E2Eテストの自動化ツールを使うことが掛け合わさってしまうと、むしろ悪い結果になりかねない。これは、傾向としてレポートが出ています。
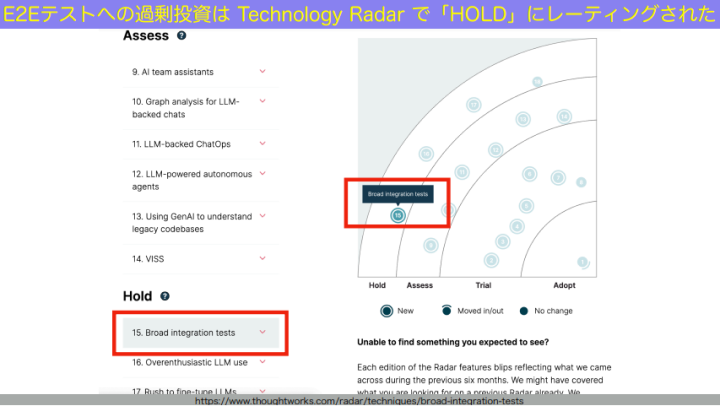
和田:thoughtworksのテクノロジーレーダーという技術動向レポートがあります。半年に1回出るものなのですが、最近のテクノロジーレーダーでは、ブロードインテグレーションテスト(≒E2Eテスト)が、Holdにレーティングされました。Holdというのは「過剰投資しがち」「やりすぎはやめよう」「これからやろうとしているんだったら少し考え直せ」というような温度感です。
なぜか? このときのテクノロジーレーダーを訳したものがこちらです。

和田:スライド1文目の「過剰投資」というのは、「ユニットテストとかいいから、とにかくE2Eテストで全部カバーすればいいんだよ」みたいな動きのこと。
過剰投資すると、それに必要なインフラなどを全部用意しなきゃいけないし(2文目)、いろんなチームがデプロイしなきゃいけないし(3文目)、失敗した時にどこが失敗しているのかよくわからないし(4文目)…といった状態になってしまう。
だから、アイスクリームコーンをピラミッドにしていくしかないのです。
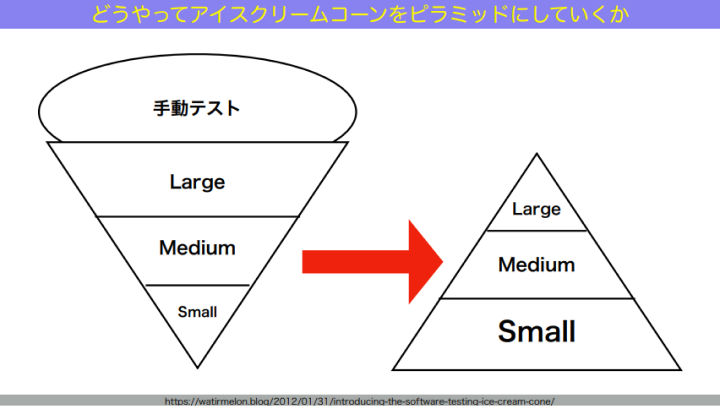
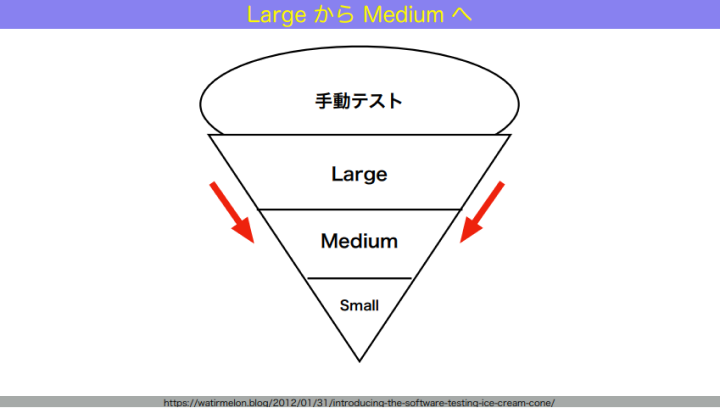
和田:最初はアイスクリームコーンでOKです。これをどうやって、システムを動かし続けながらピラミッドにしていくか。まずは、ラージからミディアムへどう移していくかを話します。
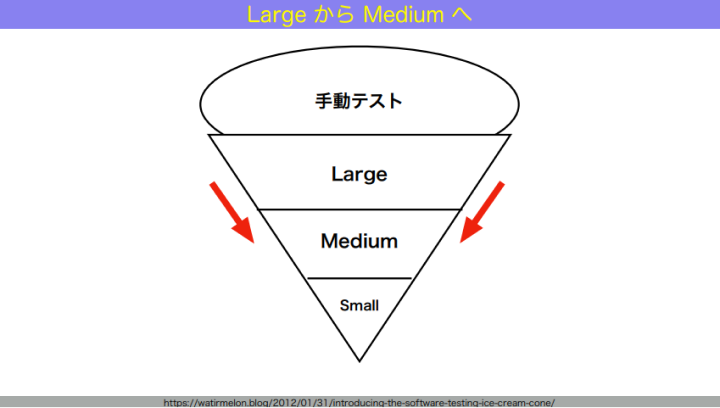
和田:ラージというのは、1つのマシンに収まらないテストでした。1つのマシンに収まらないテストをどうやって1つのマシンに収まるテストにしていくか。ここでテストダブルが出てきます。
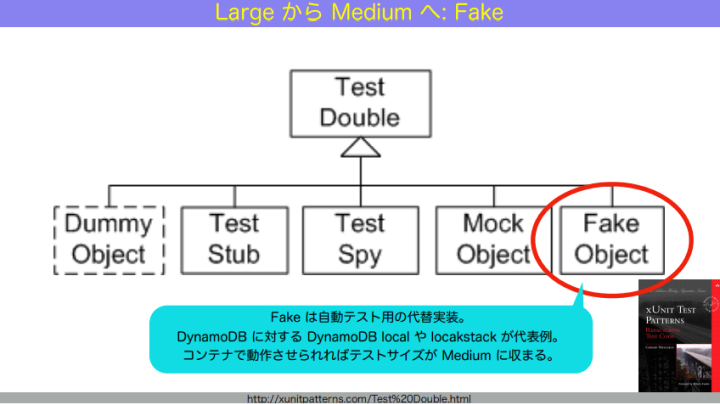
テストダブルとはつまり、テストの偽物です。mock、stub、spy、dummy、fakeといった名前で呼ばれます。これらの用語の定義はしばらく曖昧でしたが、それを明確にしたのが『xUnit Test Patterns』という本です。
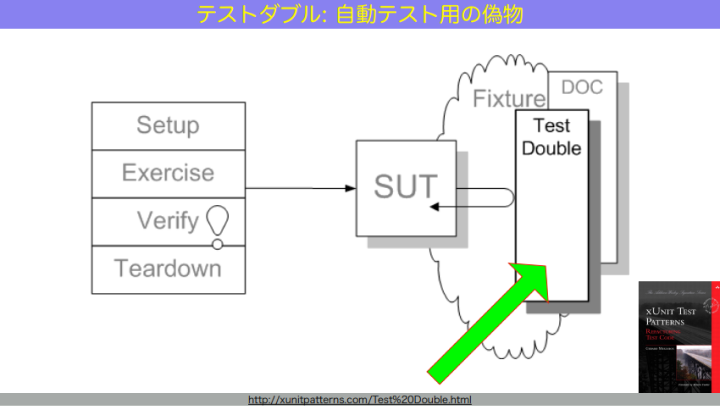
和田:テストダブルの役割は、テストしにくいものを、テスト可能にすること。例えばネットワークエラーとか disk full などは現実的に再現しづらいためテストしにくい。でもテストダブルを用いることで、そうした状況を再現してテストできるようになりますし、実際に通信するよりも速くて安定します。
でも注意点もあります。テスト対象とテストダブルの結合度が高まりすぎて、実装をいじるとすぐ失敗するようなテストになってしまったり、テストが脆くなって偽陽性を招いてしまったり。それに、自作自演テストになってしまうリスクもあります。
例えば、モックオブジェクトを自分のコードで呼び出し、その結果をテストでアサートして、結局自作自演になり、偽陽性と偽陰性をどちらとも招いてしまう場合もある。そのため、テストダブル自体は使用注意なのです。使いすぎるとテストが信じられなくなっていってしまいます。

和田:では、テストダブルは、何のために使うべきなのか? テストダブルには、「テストサイズを下げる」というものすごく大事な役割があります。
ラージテストをミディアムテストに下げる、つまり1マシーンに収まらないテストを1マシーンに収めるとき。例えば、DynamoDBを使っているロジックにテストを書くとします。DynamoDBはAmazon上にあるから、絶対ラージになる。それをミディアムに下げるには?DynamoDBの mock を自分で書こうとしても、仕様を詳しく理解しているわけでなければ、妄想が入り、偽陰性を招いてしまう。
ではどうするか。「みんながつくったテストダブル」つまり、公式、準公式や、有名なオープンソース実装などで提供されている「テスト用の偽物の実装」である fake を使うのです。例えばDynamoDBに対してはDynamoDB Localとか、S3に対しては localstack とか。これを使ってテストを書くと、信頼性をそれほど下げずにテストサイズを下げることができるようになります。
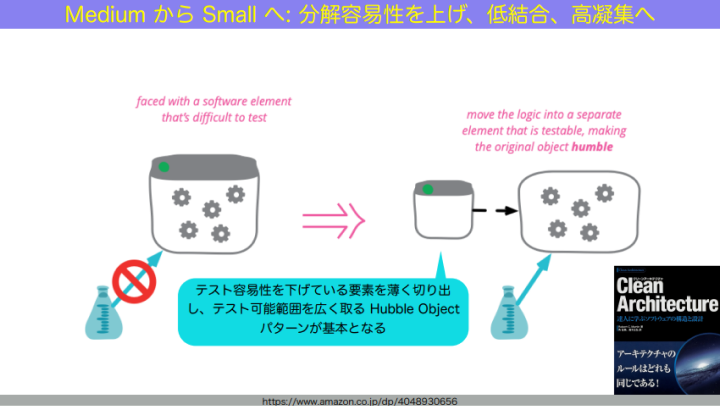
和田:続いて、ミディアムからスモールへどうやって下げていくか。つまり、1つのマシンの中で複数プロセスに渡る処理をテストしたいとき、どうやって1プロセスの中に、テストしたい要素が収まるようにしていくか。
和田:こういった場合は、設計を改善する必要があります。テストしにくいところを薄く切り離し、テストしたいところを大きく露出させることによって、テストが1プロセスの中に大きく収まるようにしていく。テストしたいところを、例えば入出力などから切り離すことによって、必然的に1プロセスにテストが収まるようになっていきます。
これは最近発売された『関数型ドメインモデリング』にも書いてありましたが、要は「良い設計をする」ということなのです。良い設計、つまり低結合高凝集の設計をしていくと、テストサイズが下げやすくなります。
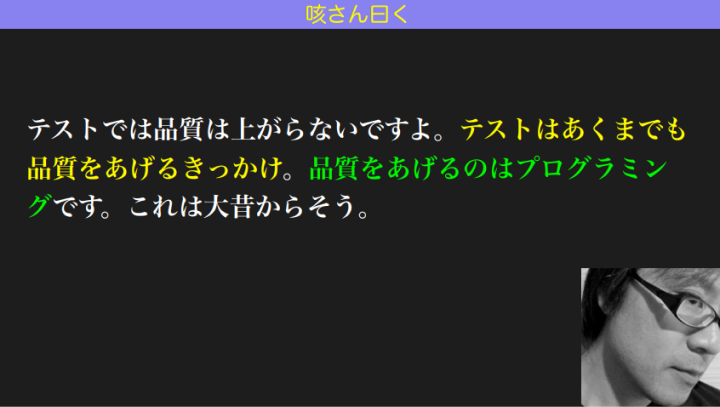
和田:ということで結果的には、良い設計をすることによって初めて品質が上がるんですね。
これは咳さんという、私が一方的にファンである人の言葉です。「テストでは品質は上がらないですよ。テストはあくまでも品質を上げるきっかけ。品質を上げるのはプログラミングです」と。これを常に心においてやっていきます。
和田:テストって体重計みたいなものなんです。ただ体重計に乗っただけでは痩せません。でも乗って初めて、今どのくらいの体重なのかわかり、その数値をもとに運動したり食事改善したりして初めて、痩せることができる。テストも同じです。テストをしただけで品質が上がるわけではなく、テストの結果を踏まえて設計やコードを改善して初めて品質が上がるのです。
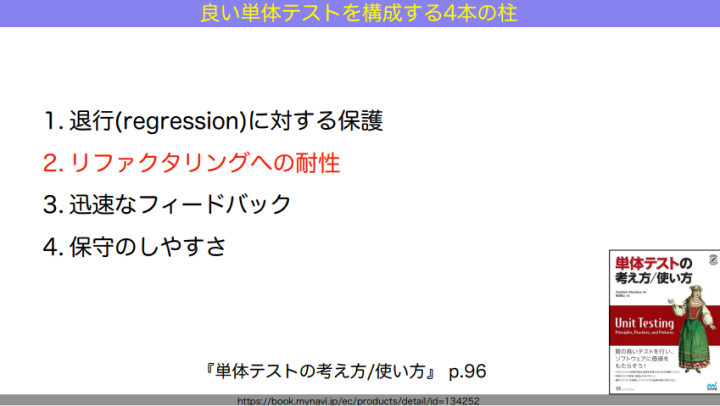
設計やコードを改善するには、リファクタリングのような変化への耐性が欠かせません。『単体テストの考え方、使い方』という本の「良い単体テストを構成する4本の柱」にも書いてあるように、リファクタリングを助けるテストを書いていくことが大切です。
変化し続ける力を得るために、テストサイズのピラミッドを構築する戦略を立てよう
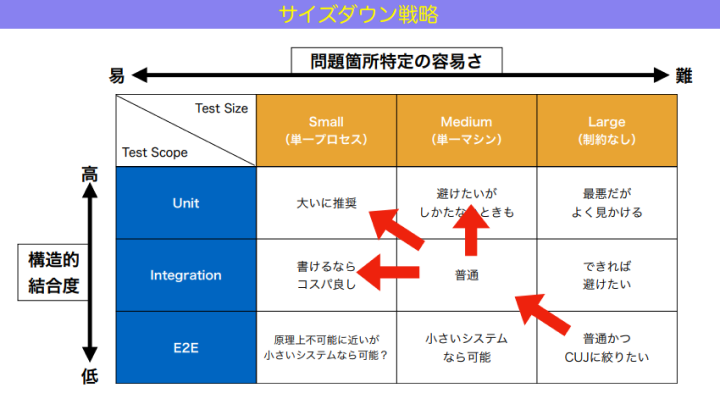
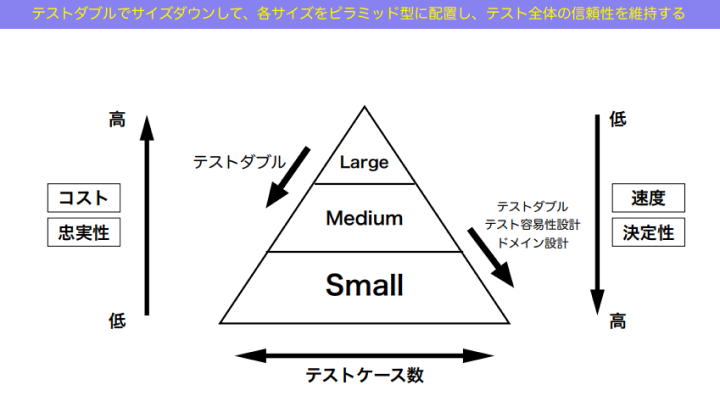
和田:では今日のまとめです。テストのサイズダウンは、こんな感じでやっていきましょう。
基本的にはアイスクリームコーン型、すなわち図の右下、ラージテストかつE2Eテストが多い状態から始まります。これをだんだん左上、ミディアム×インテグレーションに下げる。ここが真ん中ですね。それからさらに左上のスモール×ユニットとか、左のインテグレーション×スモール、上のユニット×スモールに下げていく、というような路線を取っていくのがおすすめです。アイスクリームコーンからピラミッドをつくる作戦が見えてきましたね。
和田:そして、ピラミッドはテストサイズで構成しましょう。テストサイズを下げたいときは、テストダブルを使って、ラージからミディアムへ、ミディアムからスモールへ下げていきます。
そうしてだんだんと、アイスクリームコーンからピラミッドに接近していく。最終的に「①信頼性の高い」「②実行結果に」「③短い時間で到達する」「④状態を長期的に維持する」ことを目指して、テスト戦略を立てていきましょう。
和田:私の講演は以上になります、ご清聴ありがとうございました。

編集:光松 瞳
関連記事

TDDは「開発者テストのTips集」t-wada氏が改めてひも解く“本質”

t-wada氏に聞く、テストを書き始めるための「はじめの一歩」

メルペイのテスト自動化にQAエンジニア1人で立ち向かった記録【Merpay Tech Fest 2022イベントレポート】
人気記事

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理

国産組込みOS「ITRON」が40年生き残ってきた理由を、生みの親と振り返る【TRON】

インデックスを張るだけでは足りない。数億件の名刺データを扱うSansanのSQLパフォーマンス改善

