![]()
最新記事公開時にプッシュ通知します
![]()
【新連載】生成AIで書くソースコードの著作権をどう考えるべきか?元ITエンジニアの弁護士が徹底解説
2023年8月29日


モノリス法律事務所 代表弁護士
元ITエンジニア。IT企業経営の経験を経て、東証プライム上場企業からシードステージのベンチャーまで、100社以上の顧問弁護士、監査役等を務め、IT・ベンチャー・インターネット・YouTube法務などを中心に手がける。主な著書に「ChatGPTの法律」(共著 中央経済社)・「ITエンジニアのやさしい法律Q&A」(技術評論社)・「IT弁護士さん、YouTubeの法律と規約について教えてください」(祥伝社)などがある。まんがタイムきららフォワード(芳文社)にて原作を手がける「仮想世界のテミス」連載中。
X(@tokikawase)
最近の生成AIには、文章や画像だけでなく、プログラミングコードの自動生成まで可能なものが登場しています。企業やフリーのエンジニアの中には、システム開発業務におけるこのような生成AIの活用を期待している人も多いのではないでしょうか。
しかし、生成AIに関しては、後述するように潜在的に著作権侵害の危険性を含んでいながら、いかなる場合に著作権侵害となるのかが不明確な状態が続いています。
このような状況のなか、文化庁は令和5年5月に「AIと著作権の関係等について」と題する資料(以下「本資料①」という。)を、そして翌月に開催したセミナーの資料として「AIと著作権」と題する資料(以下「本資料②」)を公表しました。著作権法を所管する官公庁が公表する資料ということもあり、生成AIに関する著作権法上の問題点に関する現状の議論を理解するためにはとても有用であるため、その概要を紹介するとともに、生成AIによりプログラミングコードを生成する場合、特に気をつけるべき点について解説します。
文化庁が発表した2つの資料のポイント
文化庁が発表した資料におけるポイントは以下の3点です。
- ・AIと著作権の関係については、「AI開発・学習段階」と「生成・利用段階」の二段階に分けて考える必要がある
・「AI開発・学習段階」は、著作権法上で適法とされている、「著作物に表現された思想又は感情の享受を目的としない利用」(著作権法第30条の4)に該当するか否かが問題となる
・「生成・利用段階」では、通常の著作権侵害と同様、依拠性・類似性の双方が満たされる場合に著作権侵害となるが、特に依拠性について、生成AIの挙動をどう捉えるべきか、見解が分かれている
詳しくは後述しますが、以下ではまず、前提となる著作権侵害の考え方について、簡単に解説します。
前提となる著作権侵害の要件とは
著作権侵害というためには、次の要件を全て満たす必要があり、1つでも満たさなければ著作権侵害とはなりません。なお、ここでは、著作権のうち、複製権及び翻案権の侵害を前提とすることとし、公衆送信権や譲渡権等のその他の権利については、ひとまず考慮しないこととします。
- (1)被侵害物品が著作物であること(著作物性)
(2)著作権者であること(著作権が誰に帰属するかという問題)
(3)依拠性・類似性が認められること
(4)権利制限規定の適用がないこと
・プログラムの著作物(著作物性)について
小説や音楽・映画など同様に、著作権法では、「プログラムの著作物」が保護されうることが明記されています。もっとも、すべてのプログラムが著作物になるわけではありません。著作権法上、「プログラム」とはソースコードのことであり、プログラム言語自体や規約・解法・アルゴリズム等はプログラムの著作物には含まれません。
重要なのは、「表現」であることです。つまり、「プログラムの著作物」として保護されるのは、コードの具体的な記述(=表現)であって、プログラムが有する機能(=アイディア)ではありません。このように、著作権として保護されるのは表現であってアイディアではない、という考え方を「表現・アイディア二分論」といい、著作権法に通底する最も重要な考え方のひとつです。
また、コードの記述に創作性が認められることも必要です。すなわち、ある機能を有するプログラムを記述するとき、誰が記述しても同じになるようなありふれた記述では著作物に当たらず、何らかの形で記述方法にエンジニアの個性が表れていることが必要です。
・職務著作(著作権の帰属主体)について
著作権は、著作物を創作した時点で、著作者に自動的に発生するのが原則です。しかし、例外的に会社の従業員として業務中に創作した著作物については、一定の要件を満たす場合、創作をした従業員ではなく、従業員を使用している会社に著作権が帰属します。これを職務著作といいます。
プログラムの著作物に関して、エンジニアが会社に雇用されている場合には上記のとおりです。フリーのエンジニアの場合、エンジニアに著作権が帰属することが原則ですが、あらかじめ契約書で著作権の帰属を明確にしておくことが望ましいでしょう。
・依拠性・類似性について
著作権侵害というためには、判例上、依拠性及び類似性が必要とされています。
「依拠」とは、「既存の著作物に接して、それを自己の作品の中に用いること」をいいます。したがって、既存の著作物を知らず、偶然一致したに過ぎない場合は、依拠性は否定されます。つまり、たまたま偶然、他人が書いたコードとほぼ同じコードを書いてしまったとしても、それが偶然であり、他人のコードに「依拠」したといえる関係がなければ、著作権侵害は成立しない、という議論です。
次に「類似」とは、他人の著作物の「表現上の本質的な特徴を直接感得できる」程度に似ていること、とされますが、その意義は明確でなく、ケースバイケースの判断とならざるを得ません。なお、プログラムの著作物については、裁判例において9割以上が一致しているか否かを基準とするものも複数ありますが、その理論的根拠等は必ずしも明確ではありません。つまり、他人のコードを見ながら(=依拠して)コードを書いたとしても、ある程度以上書き換えを行えば、著作権侵害は成立しない、という議論です。
・著作権の制限(著作権者の許諾を得ずに利用できる場合)について
他人の著作物を利用する場合、権利者から利用許諾を受け(もしくは著作権を譲り受け)なければならないのが原則です。しかし、著作権法はこの「原則」に対して、さまざまなパターンの「例外」を置いています。
例えば、「引用であれば著作権侵害には該当しない」というのは、この「例外」にあたり、「権利制限規定」と呼ばれるもののひとつです。つまり、他人の書いたコードについて、ブログ記事で解説を行うため、そのコードをブログに掲載することは、他人の書いたコードに依拠した、それと同一であり類似しているコードをブログ上に掲載する行為であって、著作権侵害である事が「原則」です。しかし、「引用」としての条件を満たした方法で掲載すれば、例外的に適法になる、という構造です。この場合、権利者の許諾を得なくても、ブログ上でコードの解説を行うことができる、ということになります。
生成AIと著作権の考え方について
前提となる著作権侵害の要件について解説してきましたが、ここからは、文化庁発表の資料をもとに生成AIと著作権の考え方を解説していきます。
生成AIにおける著作物の利用関係については、「AI開発・学習段階」と「生成・利用段階」に分けて考える必要があるとされており、いずれの段階であるかによって適用条文が異なるとされます。また、AI生成物(AIが生成したコンテンツ)が著作物に該当するか否かという点も別途問題となります。
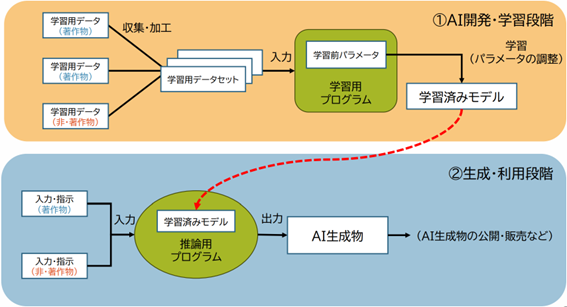
・「開発・学習段階」における著作物の利用関係
この段階では、主に次の利用行為が考えられます。
- ・著作物を学習用データとして収集・複製し、学習用データセットを作成
・学習用データセットを学習に利用して、 AI(学習済みモデル)を開発
他人の著作物をコンピュータに取り込む行為は、当該データのコピーを伴うため、原則として著作権を侵害する行為です。しかし、権利制限規定のひとつである著作権法第30条の4は、AI学習のために他人の著作物をコンピュータに取り込む場合には、「著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」のひとつである「情報解析」として、例外的に著作権侵害とならないと規定しています。学習用データはときに数十億点にもなり、すべての著作権者に対して個別に許諾を得ることが困難・非現実的であるためです。
ここで重要なのは、「著作物に表現された思想又は感情の享受を目的としない利用」であるか否かであり、「享受」とは、著作物の視聴等を通じて、視聴者等の知的・精神的欲求を満たすという効用を得ることに向けられた行為であると考えられています。享受といえる典型的な行為としては、文章の著作物であれば閲読することであり、プログラムの著作物であれば実行することが挙げられます。
通常、著作物に対する利用料等は、このような効用を得られることへの対価として支払われており、逆から言えば、そのような効用が得られないような利用行為に対しては、本来的に著作権者の経済的利益は生じないはずなので、自由に利用させても著作者への不利益は小さい、ということです。
ただし、「著作権者の利益を不当に害することとなる場合」(著作権法第30条の4ただし書)は例外の例外です。例えば、情報解析用に販売されているデータベースの著作物などのように、情報解析用としてのライセンス市場が成り立っており、権利制限規定により許諾なく利用できるとしてしまうと著作権者の利益を不当に害するおそれがある場合です。最終的には司法の場で個別具体的に判断されますが、学習用データとして著作物を利用する場合であっても、すべてが権利制限の対象となるわけではないため、注意が必要です。
・「生成・利用段階」における著作物の利用関係
この段階では、主に次の利用行為が考えられます。
- ・AIを利用して画像等を生成
・生成した画像等をアップロードして公表、生成した画像等の複製物(イラスト集など)
を販売
AIを利用して画像等を生成する場合であっても、著作権侵害の判断基準は異なりません。したがって、前述のとおり、➀生成された画像等が既存の著作物と同一又は類似であり(類似性)、➁当該既存の著作物に依拠したといえる場合(依拠性)には、著作権侵害となります。
このように、基本的には通常の著作権侵害の判断と異ならないが、AIによって画像等を生成する場合には、プロンプト(指示)を入力するという人間の作為が開示するという特殊性があります。つまり、プロンプトに他者の著作物を入力して、当該著作物と類似する画像等が生成された場合には、類似性も依拠性も認められる可能性が極めて高いのに対して、プロンプトに他者の著作物を入力したわけではなく、学習段階で参照されていたにすぎなかったものの、偶然類似する画像等が生成されてしまった場合、依拠性が認められるのかが問題となります。
この点、AIの推論過程はブラックボックスであるから、学習用データにそもそも当該著作物が含まれていなかったことが立証できる場合は別として、その主張立証は容易ではありません。学習用データに含まれているだけで依拠性を認めるべきであるという見解や、学習段階でパラメータ化されている場合にはもはや表現でなく、表現に依拠していない以上、依拠性は認められないという見解も主張されており、議論の渦中です。
ただし、類似性及び依拠性が認められた場合であっても、権利制限規定である著作権法47条の5は、電子計算機により情報解析と結果の提供を行うための「軽微」な利用については著作権侵害とならない旨定めています。とはいえ、「軽微」であるか否かも、基準としては曖昧であり、判断が難しい場合が多いでしょう。
AI生成物の著作物性
仮にAI生成物に著作物性が認められないとすると、例えば、AIを利用していくら魅力的なコンテンツを制作したとしても、他者によるフリーライドを許すことになってしまいます。AI生成物に著作物性が認められるかは極めて重要な問題です。この点、AI生成物に著作物性が認められるか否かは、一般に人間がAIを道具として利用したにすぎないのか否か、具体的には、人間の「創作意図」「創作的寄与」の程度によって判断されるものと考えられています。
つまり、イラストの場合、PCで描かれたイラストにも著作物性は認められますが、これは人間がPCやソフトウェアを「道具として利用した」のみであり、そこに人間の「創作意図」「創作的寄与」が多く存在するからです。ただ、AIに対して単に例えば「向日葵の花の絵を描いて」と指示して絵を描かせただけでは、人間による十分な「創作的寄与」があるとは評価できないでしょう。こうした理論が、プログラムに関しても同様に問題となります。
どの程度の創作的寄与があれば著作物性が認められるかは明らかではありませんが、抽出すべきデータの選択等において相当程度、具体性のある指示が必要であると考えられます。しかし、推論能力が高いAIの場合には、仮に相当程度具体性のあるプロンプトを入力した場合であっても、人間の創作的寄与が否定される可能性も否定できません。
このように考えると、AI生成物をそのまま利用するべきではなく、人間による明確な創作行為を介在させた方が、その生成物に関する著作物性が明確になるとは言えます。
生成AIによるソースコードの自動生成とOSSの関係について
AIがソースコードを生成する場合に特に問題となるのは、OSSなどのライセンスに関する問題です。AIがソースコードを自動生成する場合、その前提として他者のソースコードを学習しているわけですが、その多くはOSSとして公開されているものに依拠しています。
OSS(Open Source Software)とは、作成者がソースコードを無償で公開していて、利用や改変・再配布に許可されているソフトウェアのことです。OSSについては、たまに誤解されていることがありますが、「OSSであれば著作権侵害の問題は生じない」というわけではありません。前述のとおり、ソースコードには著作権が発生しうるのであって、OSSは、「一定の条件で著作物であるソースコードの利用を許諾するもの」にすぎないのです。したがって、この「一定の条件」に反する利用は、著作権侵害の問題が生じうることになります。
AIによって自動生成したソースコードがOSSとして公開されている他者のソースコードに類似している場合、自動生成した当該ソースコードを利用するためには、前述の「一定の条件」を守らなければなりません。OSSを通常利用する場合には、利用者にOSSを利用していることの認識が存在するため、条件を遵守することに対する動機が明確です。AIによって自動生成する場合には、このような認識及び動機を欠くことがほとんどであると推測されます。その結果、「知らないうちに著作権を侵害していた」という事態が発生しやすいと考えられます。
したがって、現状としては、AIによって自動生成したソースコードをそのまま利用することは著作権侵害のリスクが大きいため、避けるべきです。一方で、昨今では、ソースコードを自動生成するだけではなく、ソースコードを自然言語で読解してくれるAIも登場しています。そのため、既存コードのレビューやドキュメントの作成において、このようなAIを利用することがエンジニアにとっては現状有効なAIの活用方法と言えるでしょう。
関連記事

【「スゴ本」中の人が薦める】ITエンジニアなら知ってほしい。プロジェクトを炎上させないマネジメント術を身につける4冊

【ChatGPT✕サイバーセキュリティ】ChatGPTはネット世界の安全を脅かす存在になるか【テッククランチ】

伊藤淳一氏が「一番下手くそエンジニア」から脱出した4つの方法。2023年版ITエンジニアの生存戦略【後編】
人気記事

【3/26(木)オンライン開催!】Rust いまのアーキテクチャにどこから入れる? ~ yukiさん、kenkooooさんが部分導入の“最適解”を語る夜 ~

世界屈指の「ランサムウェアに金を払わない国」なはずの日本にサイバー攻撃が増えている理由【上原哲太郎&増田幸美】

「何の役に立つの?」と図形問題を避ける次女。学習モチベを上げた「算数のスキルツリー」整理


