![]()
![]()
W杯全64試合無料生中継で「落ちない」を実現。「小さく壊れる」ために行った負荷・障害・セキュリティ対策とは?【ABEMA DEVELOPER CONFERENCE 2023#3】
2023年5月25日


株式会社AbemaTV Software Engeneer
辻 純平
2013年サイバーエージェント入社。2018年からABEMAのAPI開発チームに異動。W杯負荷対策ではAPI、データ基盤などのアーキテクトとして活動し、現在はSREとして従事。
日本代表の躍進に日本中が沸いた、2022年の「FIFA ワールドカップ カタール 2022」(以下、W杯)。ABEMAにて全64試合の無料生中継が行われたことも注目を集め、同社史上最大の同時接続数を記録した。さらに、中継が落ちるなどの大きなトラブルがなく全試合を完走したことも大きな話題となった。
本記事では、ABEMAのソフトウェアエンジニアを務める辻純平氏によるセッションを紹介する。W杯生中継においてエンジニアチームは、どのような負荷・障害・セキュリティ対策を行なったのか。
大規模配信を成功させるための意識・施策
辻氏はセッション冒頭で、W杯配信にあたって、エンジニアチームでは以下の5点を対策として行ったと述べ、セッションはこの5点を順番に解説する形で進められた。
・イベント対策を行う上で重要なことは何かを見極める
・シーケンスとクリティカルAPI
・小さく壊れるためのアーキテクチャ改変
・ピーキースパイク対策
・セキュリティ対策
大規模イベントでサービスが落ちてしまうと、短期的にはユーザーが配信を見られないことで集客・残存における機会損失が発生し、長期的にはブランドイメージの悪化によってユーザーのみならず、提携事業者からの信頼も損なってしまう。
そのため、「システムの一部に問題が発生しても、サービスの価値を提供するコアとなる機能はダウンさせないシステムを構築しなければならない」と辻氏は語る。

こうした大規模なイベントを行う上で、対策を意識するべき重要な4つのポイントを以下に挙げている。
・システム障害やキャパシティ不足でサービスを落とさないこと
・規模が大きいことで、普段よりも急激なリクエストが発生すること
・認知されやすいため、悪意ある攻撃者の対象になりやすいこと
・対策の費用対効果が適切であるかどうか
シーケンスとクリティカルAPI
ABEMAのようなコンテンツ配信サービスにおいて、負荷が集中しやすい箇所は「認証」「視聴権限チェック」「構成要素の多いホーム画面」の3点だという。視聴に至るまでのユーザーシナリオは多岐にわたるため、ダウンさせないシステムを構築するには計測・分析が不可欠だ。
負荷の予測に当たっては、事前に「どのAPIがどれくらい重要なのか」を概算するため、まず全ユーザーシナリオごとに呼び出されるAPIを洗い出したうえで一覧化。そこから視聴までに必須となるクリティカルなAPIを洗い出すシーケンス分析を行い、APIごとに障害発生時の影響度を把握したという。

さらに、各APIがイベント期間中にどれくらい呼ばれたか、ピーク時の最大RPSはいくつかといったアクセスログ分析を行い、どのAPIにおいて障害発生リスクが高くなるかを可視化している。合わせてAPIごとのトラフィック割合やスパイク傾向を洗い出すトラフィック分析も実行した。
これにより、「ボーリング頻度が短いため、実は結構なトラフィックになっていた」などの意外なリクエストも明るみになったと辻氏は回顧する。
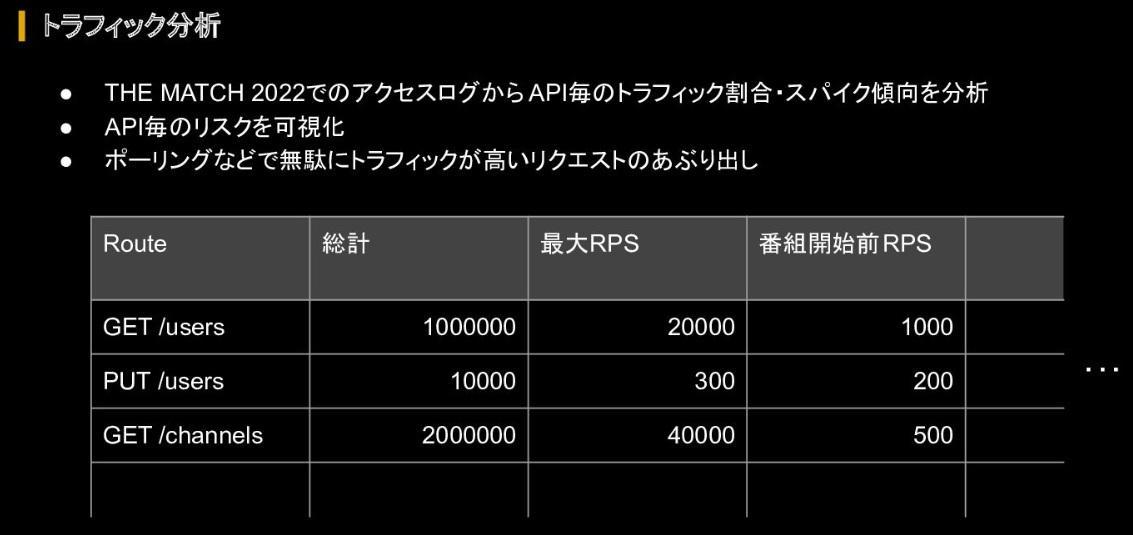
これらのデータをもとに、「クリティカルパスとなるAPIは必ず守る」「スパイク対策は必須」「ポーリング間隔をサーバーサイドでコントロールし、不要なトラフィックを削減」といった方針を策定し、次ステップとしてアーキテクチャの改変を行った。
小さく壊れるためのアーキテクチャ改変
大きく壊れる要因
ABEMAは開発当初から巨大ドメインになることが想定されていたため、同社で提供する各サービスにおいてデータベースが共通利用されている部分があったり、特定のマイクロサービスへの依存が多かったりといった構造上の課題を抱えていた。
このような設計では、データベースやサービスの共通利用によりキャパシティの計算が難しくなったり、一部のサービスが落ちると他サービスも連鎖的に落ちてしまったりといった運用上の問題にもつながってくる。
さらにはリクエスト数が多くなりキャパシティの上限に迫ると、レイテンシが劣化してリクエストがそのサービス内で滞留し続け、最終的にアウトオブメモリー(メモリ不足、以下OOM)が発生する。
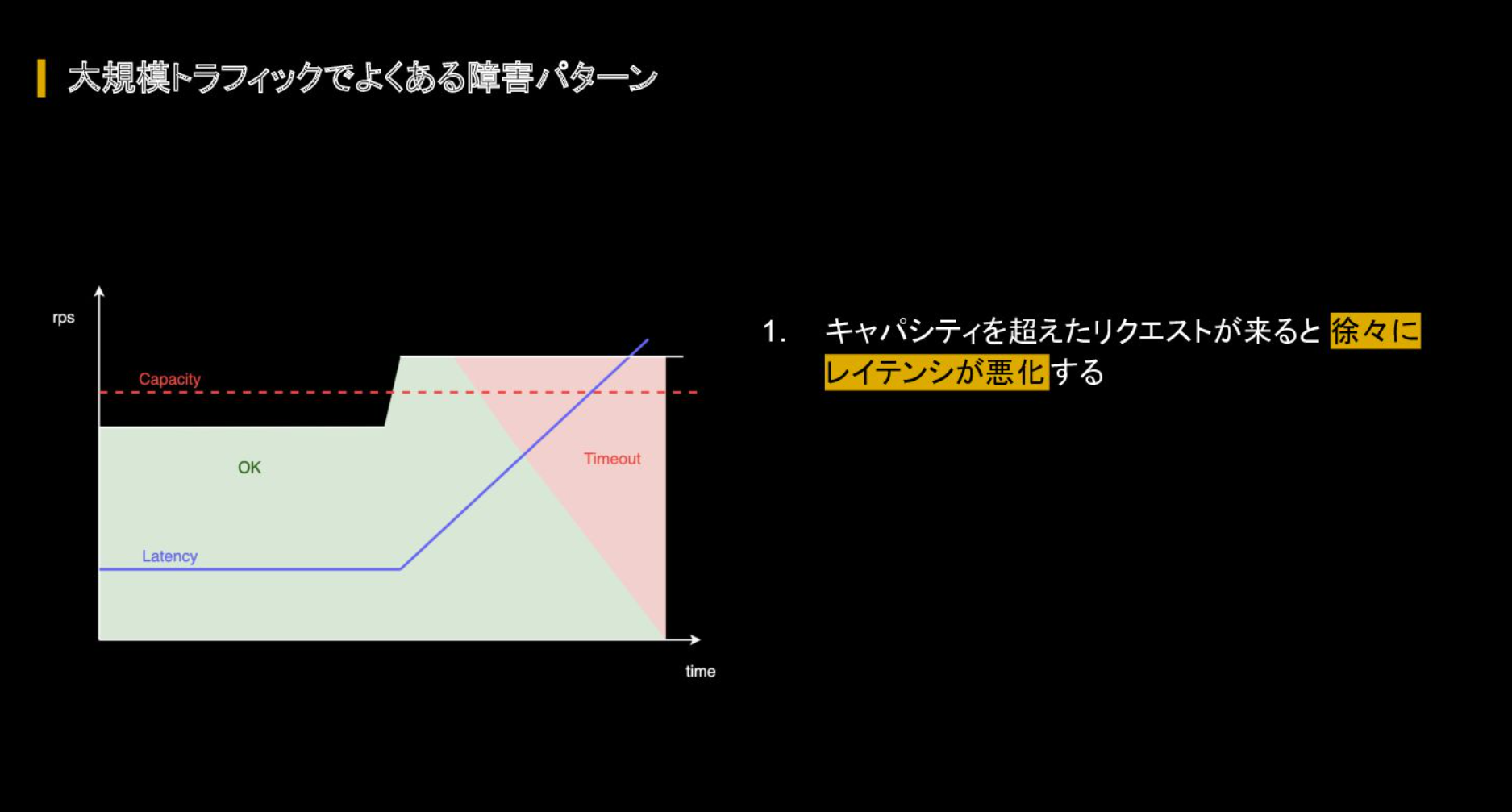
実際に行った負荷試験においてもOOMは発生した。捌ききれなかったリクエスト処理は残ったPodで対応しなければならないため、このパターンに陥ると各Podは通常の数倍ものリクエストを捌く必要があったという。そのうえ、落ちたPodを再起動させる間に他のPodが落ちていき、再起動したPodもキャパシティを超えたリクエストに耐え切れずまた落ちるという「負のスパイラル」が発生したと振り返る。
こうした負のスパイラルを脱するには「問題が起きても、そこだけで留めることが重要」だと語る辻氏。ABEMAでは「Blast Radius of Failuresの最小化」、つまり「小さく壊れること」をユビキタス言語として共通認識をとっていたと回顧した。
サービスとデータベースの分割
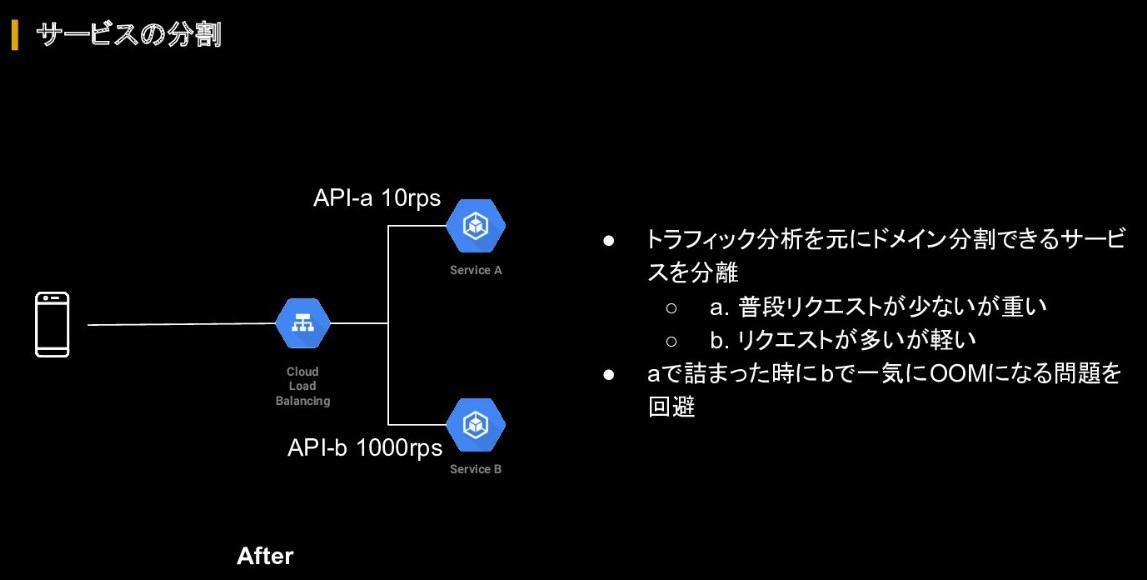
小さく壊れるための施策として、まずはトラフィック分析を基に、ドメイン分割できるサービスを分離させた。これによりあるAPIが詰まった際に別のAPIでも連鎖的にOOMが起きるという問題を回避した。
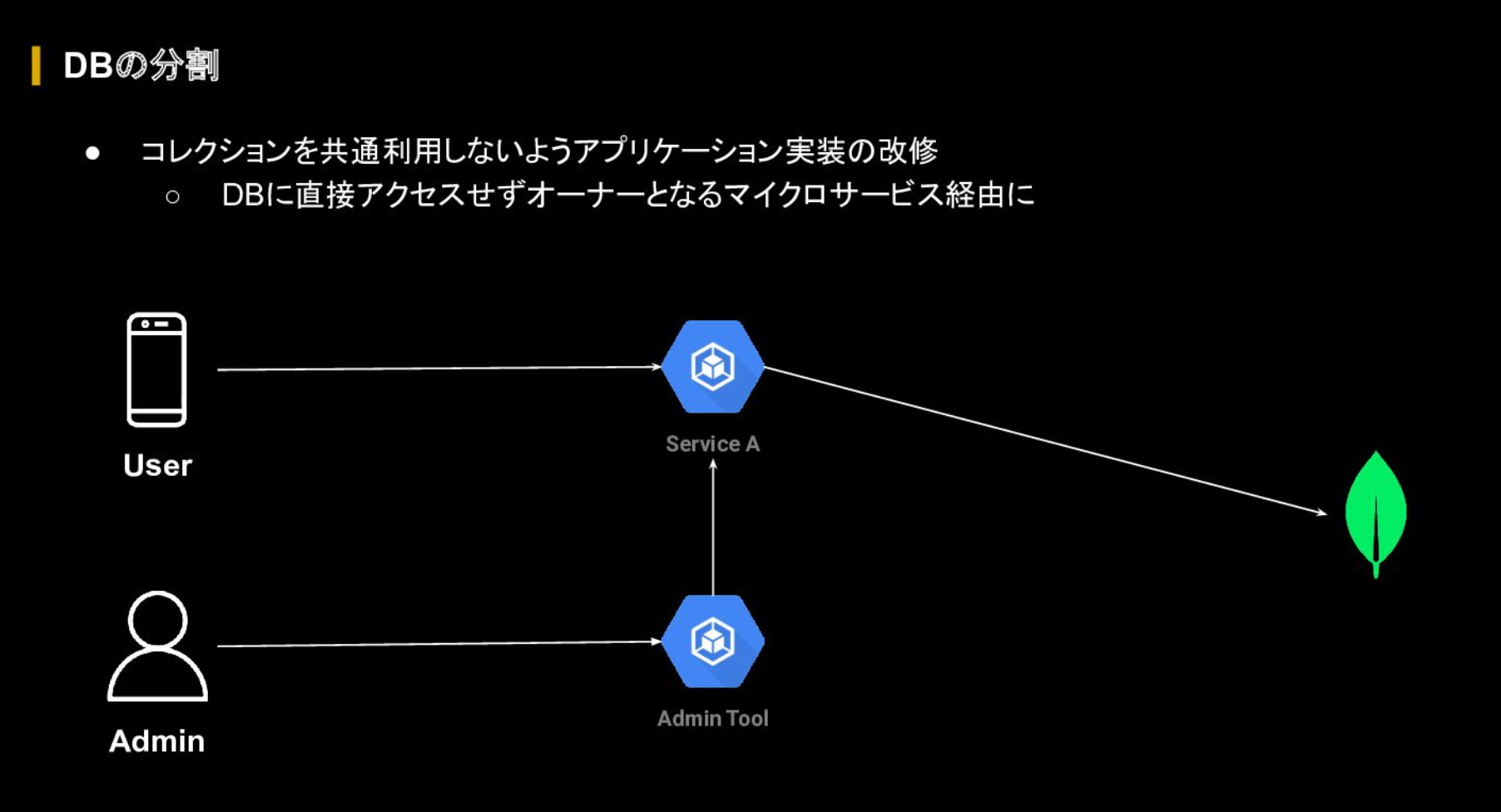
また、過去のイベントでは、データベースを複数のマイクロサービスで共用利用していることが大きく壊れる要因となっていた。そのため、マイクロサービスごとの利用コレクションやトラフィックなどを洗い出して分析したうえで、データベースの分割も行った。
中には複数のシステムで同じコネクションを共通で利用していたことから、アプリケーションの改修を行い、オーナーとなるマイクロサービスを経由するように修正した。辻氏はこうしたデータベースの分割について、「大抵のデータベースは水平スケールができないか大変なパターンが多いため、共通利用だとスケール限界がくるのでサービス毎の分割を推奨する」と所感を述べた。
さらにGoogle CloudのデータベースであるFirestoreでは、他のマネージドデータベースと違って1プロジェクトにつき1つのデータベースしか使用できないという制約がある。そのためサービスごとにGoogle Cloudプロジェクトを個別に作成することで、「共通利用によって大きく壊れやすい」という問題を回避した。
サーキットブレイカーとタイムアウト
次に行なったのはサーキットブレイカーの設定だ。これは特定のPodが落ちた際のトラフィックが他のPodに影響しないよう、閾値を超えたリクエストには即座に503エラーを返す、レートリミットのような仕組みで、これによりPodを落とすことなくリクエストを捌き続けることができる。さらに、できる限り不確実性を下げるべく、スケールコントロールができない外部APIに対してもサーキットブレイカーを適用した。
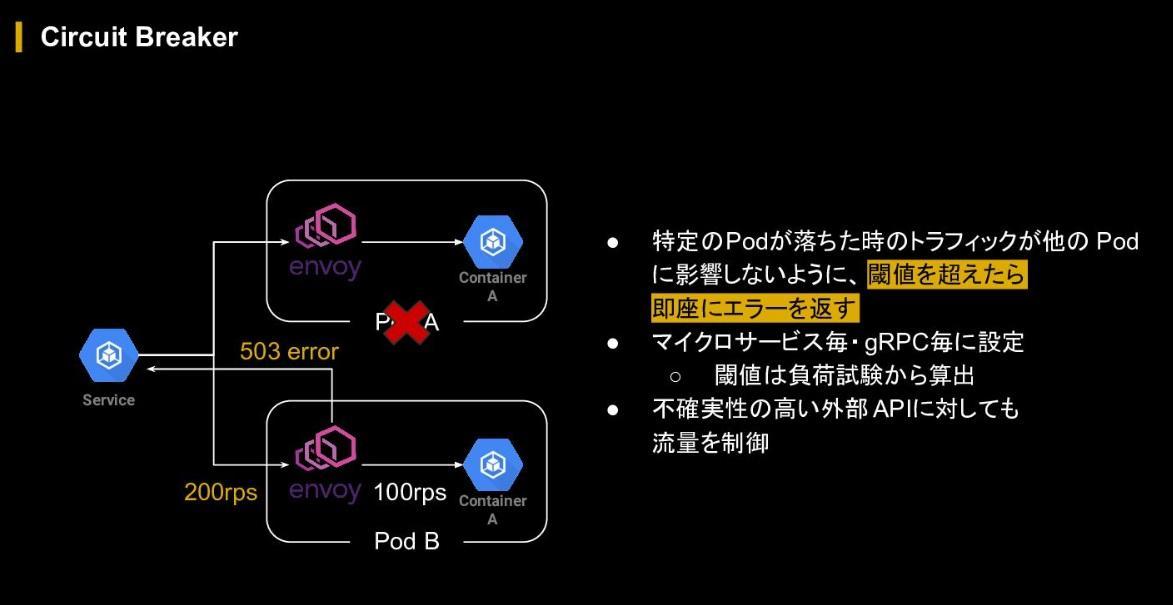
SLO(サービスレベル目標)をアベイラビリティとレイテンシに置いている多くのサービスでは、アベイラビリティ向上のため自動リトライを入れているものも多い。ABEMAでも自動リトライを入れているものの、辻氏は「大規模イベントではこれが首を絞めることもある」と警鐘を鳴らす。自動リトライを入れると内部でリクエストが滞留するため、結果的にOOMのリスクが上がるというのがその理由だ。
辻氏は落ちないことを優先するべく、あえて自動リトライは入れず、さらにはタイムアウトの時間を出来る限り短くする方法をとった。タイムアウトエラーが増えると、バックエンドの視点ではアベイラビリティは下がるものの、ユーザー視点では必ずしもそうではない。タイムアウト時間が長いことで「レスポンスが返ってこない」という体験はアプリの再起動や離脱につながる。「ユーザー体験の向上を考えると、タイムアウトを短くする方がリスク低減につながる」と説明する。
とはいえ一律で短くする方がいいわけではなく、課金シーケンスのような場合は、ユーザーも待機する傾向があるため、こうした場合は自動リトライやタイムアウトを長めに設定してアベイラビリティの向上を優先させるべきだとした。
加えて、内部的なエラーを返す代わりに他のコンテンツを用意して返す「フォールバック」も実装。これは、例えばユーザーのアクションに対しパーソナライズ化されたコンテンツが返される仕様のシステムにおいて、エラーやタイムアウトなどの問題が発生した際にあらかじめキャッシュしておいた代替コンテンツを返すというものだ。
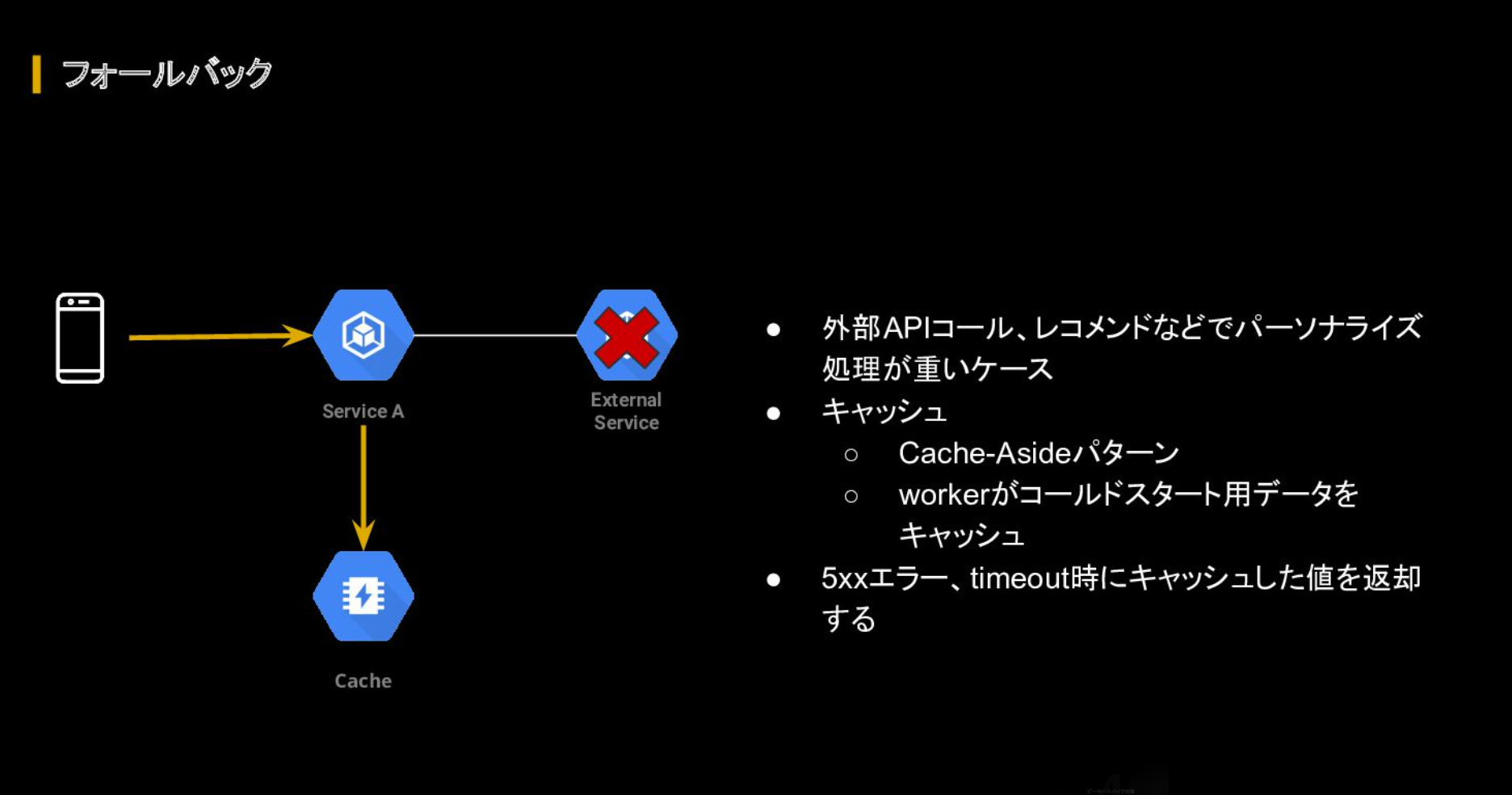
この仕組みがあれば、外部APIコールやレコメンドなどパーソナライズ処理の重い動作を行なって問題が発生した時にも、「アベイラビリティを保ちつつ、OOMのリスクを下げることができる」と語った。
実運用での問題
ABEMAのマイクロサービスでは、サーキットブレイカーや自動リトライといった機能の運用負荷を下げるため、Anthos Service Meshという、Google CloudのIstio ベースのフルマネージドサービスメッシュを使っている。しかし、実運用においては、データベース側のメトリクスのレイテンシが低いにも関わらず、E2Eでのレイテンシがとても遅くなっており、分散トレースで確認するとデータベースアクセス時のレイテンシが600~800msと異常に遅くなる事象に遭遇したという。
マイクロサービスとデータベースのメトリクスは問題ないことから、中間にいるSidecar自体が良くないという仮説を立てた。しかしながらSidecarのリソースを増やしても改善せず、最終的にSidecarを経由しない設定にしたところ解決した。結論として、データベースのような大量のIOが発生するユースケースの場合は、Istio Sidecar自体がボトルネックになってしまったと振り返る。

ピーキースパイク対策
イベントでは配信開始タイミングやCM明けに急速なユーザー流入があり、リクエスト量は爆発的に増加する。こうしたピーキースパイクに関して、オートスケールが間に合わないという点が大きな課題となっている。辻氏は「おそらくバックエンドの方ならどなたも悩まされていると思う」と指摘する。
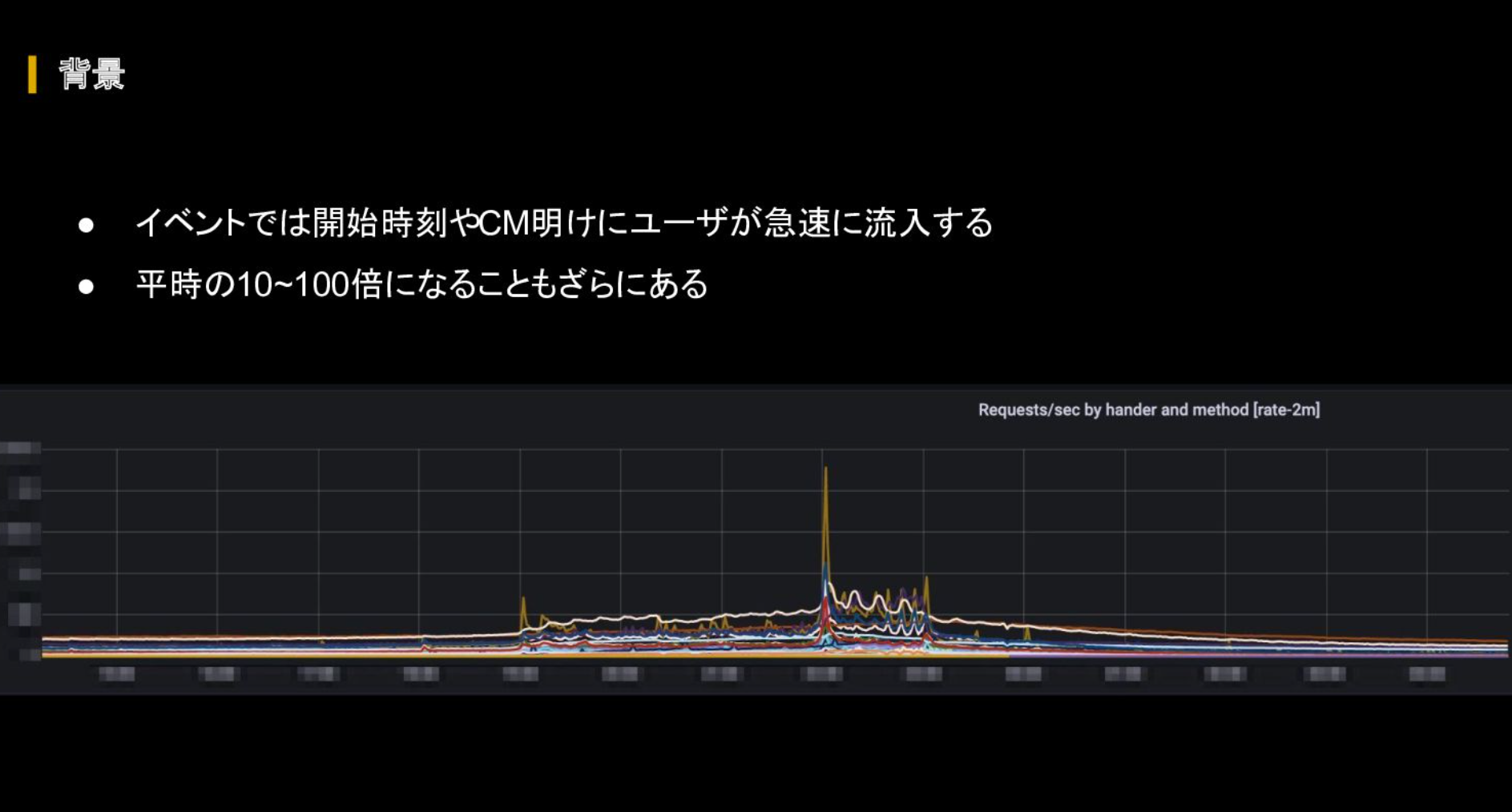
とはいえスパイクのために高いキャパシティを常設するとシステムコストが高騰し、費用対効果が悪くなってしまう。「この日にイベントを行う」という周知がなされていればスケジュールされたオートスケールなどでも対応できるが、実際のところは、Twitterなどでバズって想定外のスパイクが来るケースや、そもそも周知されていない場合もあるため、スパイクに対する正確な予測はできずオートスケールも間に合わないのが現実だ。
そこでABEMAでは、ユーザーの起動や復帰シーケンスにCDNレイヤでスロットリングをかけることでスパイクに対しての閾値を設定することにした。閾値を超えると、バックエンドシステムにリクエストが到達しないよう設定し、急激な負荷がかからないようにしているという。
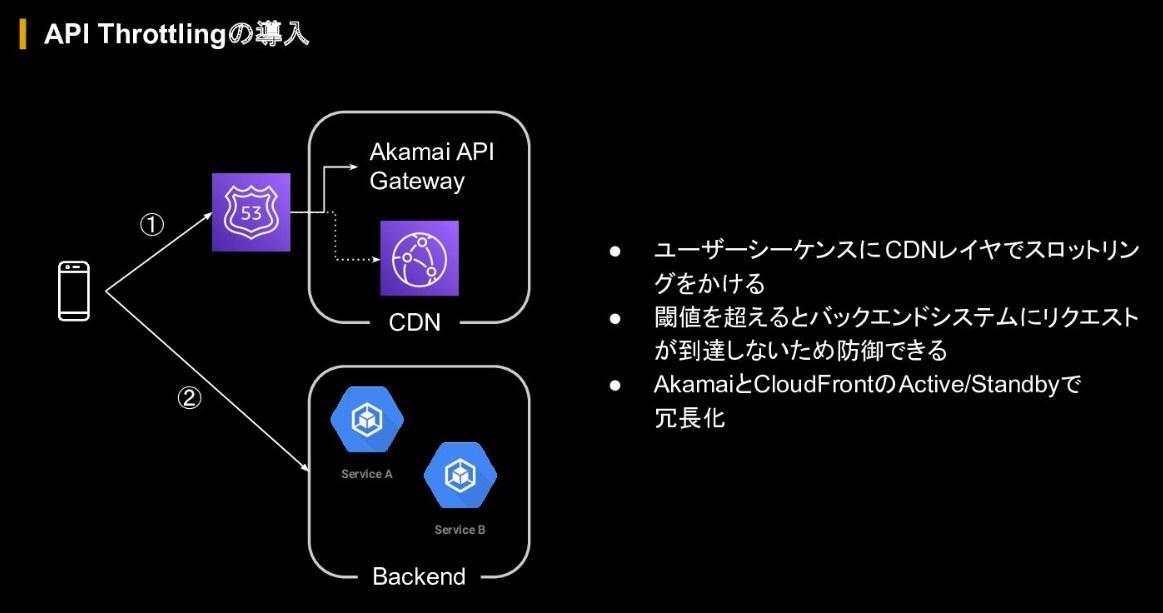
この仕組みでは、一時的に入れないユーザーは発生するものの、秒間でのスロットリングのため、「待機していれば自動的に入れる」もしくは「アプリを再起動すれば入れる」程度の待ち時間になっている。これならば、システムが落ちて全体に視聴影響が出るよりも断然よいという判断のもと運用しているという。
セキュリティ対策
セキュリティについては、イベントが大きければ大きいほど攻撃者に認知されやすく、落ちた時のビジネス影響も大きくなる。
したがって攻撃者のモチベーションも上がりやすいうえ、現在はさまざまな攻撃手法があるため、攻撃手法によってその対策も異なることから網羅的に防御することが難しいという課題が挙げられた。またこうした対策はいたちごっこになりやすく、間違った防御ルールを設定すると、誤検知により一般ユーザーに迷惑がかかる可能性がある。
例えばDDoS攻撃の場合、L3/L4/L7において帯域を枯渇させるボリューム攻撃、リクエストをサーバーまで到達させてサーバー側のコンピューティングリソースを枯渇させる演算処理を消費する攻撃、サーバー側はクライアント側よりも多くのリソースや帯域を必要とするという非対称性を悪用した非対称攻撃、システムやプロダクトの脆弱性をついた脆弱性攻撃の大きく4種類がある。

Google Cloudが標準的に防御している部分もあるものの、カバーできない部分はABEMA側で機械学習を用いた攻撃対策を導入しており、通常時とは異なるトラフィックが来た場合に通知が来るという体制を敷いているという。

さらに、自動的に防御ルールが生成されるため、サービス側は数クリックで新たなブロックルールを適用できる。それに加え、オープンソースの業界標準から集められた脆弱性対策のためのルールも用意されており、感度レベルを調整することで誤検知を手動で調整できる仕組みが構築されている。
今後の取り組み
辻氏は今後について、「大規模な対策を導入したものの、それが今後も継続されていくか、陳腐化していくかが肝になってくる」と語る。講演の最後に、継続的に進化するための仕組みやシステムとして、負荷試験をCIに組み込んだり、障害試験を実施したりすることによって小さく壊れることが保証されるようにしていきたいとした。

一方で、単純にそれらを行ってもチームの生産性が下がってしまうため「生産性が下がらないよう適切なサービス分割を行ったり、それがチームのモチベーション向上やインセンティブになるような仕組みであったり、文化づくりを進めたいと思っている」と、今後の展望に意欲を見せた。
文:中島 佑馬
関連記事

過去最大トラフィックを完走。W杯配信キャパシティ確保の裏側【ABEMA DEVELOPER CONFERENCE 2023#1】

最高の視聴体験を届ける。「見せ方」を意識したプロダクト設計【ABEMA DEVELOPER CONFERENCE 2023#2】

【LayerX・バクラク事業部CTO/CPO】爆速開発を支えるバクラクチームとアーキテクチャのつくり方
人気記事

Zustand、Jotai、Valtioの作者はなぜReact状態管理OSSを3つ開発したのか【フォーカス】

【7/23(水)オンライン開催!】Devin/Cursor/Cline全社導入 セキュリティリスクにどう対策した?

Rubyへの型導入、実際にどんな利点がある? 壊さず進める大規模コード改善の実践知

